keystone-enclave软件实现分析
我分析的是git哈希值为 4e966526cdcb464ad3faf8cfd1b12ca3013a2103 的keystone仓库的代码。读者可以在前言的环境搭建部分拉取我准备好的docker镜像。建议读者阅读前言部分。
前言
声明
本文以及B站视频的所有法律权利为本人所有,未经授权严禁转载。本文以及B站视频可以自由用于非营利性用途,但需注明出处。
前置知识
Keystone enclave牵涉的知识比较多,为了读者能够更顺利的阅读理解以及实现,希望读者能够事先掌握以下知识:
- riscv特权级切换
- 阅读riscv sbi SPEC
- 内存管理原理以及riscv页表的实现方法(精通虚拟地址、物理地址之间的转换)
- 对可信执行环境有基本的认识
- 熟悉OS中中断和系统调用的实现
- 熟悉Linux driver中
ioctl机制 - risc-v汇编语法
请确保你掌握了入门指南中的内容
总的来说,需要学习三个方面的内容:RISC v spec、研读xv6-riscv代码、学习Linux driver编程。
参考资料
- 《RISC-V架构与嵌入式开发快速入门》主要看附录AB
- **RISC-V Assembly Programmer's Manual**极简
- RISC-V REFERENCE 指令列表与简要说明
- RISC-V指令手册 包云岗老师翻译的
- RISC-V ASSEMBLY LANGUAGE Programmer Manual Part I 非常详细的一本书
- RISC-V-Guide 总结了各种RISC-V的资料
- an-introduction-to-assembly-programming-with-risc-v
- Control and Status Registers (CSRs)
名词解释
normal world: linux kernel + host app
Secure world: runtime/secure os + eapp(enclave app)
Runtime in secure world: trusted runtime(tRuntime, trts)
Runtime in normal world: urts(untrusted)
| 名词 | 解释 |
|---|---|
| APP | application |
| eapp | Application runs in enclave |
| Host app(happ) | Application runs on rich OS |
| enclave runtime(或者在后文中简称runtime) | enclave的运行时,eapp依赖于该运行时,本质上就是个小型的OS内核,在后文中会将runtime和TEEOS混用。要注意,每一个eapp都对应有一个runtime。 |
| UTM/utm | Untrusted memory,用于host与enclave之间的数据传递 |
| SM | Secure monitor |
| 在后文中,enclave有时指安全内存,有时指安全内存中运行的安全进程,读者需要注意区分。 |
环境搭建
官方也准备了docker,可以参见链接,但是我建议使用我准备好的docker,我的docker的代码版本跟官方的不太一样。官方教程:
1.2.1. Testing Keystone with QEMU ‒ Keystone Enclave 1.0.0 documentation
拉取我准备好的docker:
docker pull registry.cn-hangzhou.aliyuncs.com/loongenclave/keystone-enclave:latest
docker run -it --name keystone-enclave registry.cn-hangzhou.aliyuncs.com/loongenclave/keystone-enclave:latest zsh
cd /keystone
. ./source.sh
cd build
make -j$(nproc)
make run-tests
执行完make之后,就再也不要执行了,否则会报错。此时所有的二进制文件都已经构建完成了。
其它
文中的很多图是使用plantuml语言绘制的,原始plantuml保存在gitee上(不开源):
https://gitee.com/wangzhankun/keystone-enclave-docs
RISC-V分页技术
这里只做很简单的描述,更多内容参见SV39 多级页表的硬件机制 - rCore-Tutorial-Book-v3 3.6.0-alpha.1 文档
Keystone enclave需要为enclave内存空间建立页表,runtime和eapp共用同一份页表,也就是说S-MODE的runtime和U-MODE的eapp处于同一虚拟内存空间。
keystone enclave虚拟地址转换采用的是SV39,支持512GB的虚拟内存。

- V位表示PTE是否有效;如果为0,则PTE中的所有其他位都无关紧要,可由软件自由使用。
- 权限位R、W和X分别指示页面是否可读、可写和可执行。当三个都为零时,PTE是指向页表的下一级的指针;否则,它是叶PTE。可写页面还必须标记为可读。试图从一个没有执行权限的页面获取指令会引发一次取页面错误异常。试图执行一个加载或加载保留指令,其有效地址在没有读权限的页面中时,会引发一次加载页面错误异常。试图执行存储、条件存储或原子操作(AMO)指令,其有效地址在没有写权限的页面中时,会引发一次存储页面错误异常。

- U位指示页面是否可由用户模式访问。U模式软件只能在U=1时访问页面。如果设置了SSTATUS寄存器中的SUM位,S模式软件也可以访问U=1的页面。然而,S模式的代码通常在SUM位清零的情况下运行,在这种情况下,管理程序代码将在访问用户模式页面时出错。无论SUM位如何,S代码都不能在U=1的页面上执行代码。
- G位表示全局映射。全局映射就是说存在于所有的地址空间中的映射。对于非叶PTEs(页表项),全局设置意味着所有后续级别的页表中的映射都是全局的。需要注意的是,未将全局映射标记为全局,仅仅会降低性能,而将非全局映射标记为全局则是一个软件错误,在切换到具有不同非全局映射的地址空间后,可能会产生无法预测的结果,从而导致使用其中任意一个映射。
- A和D分别表示access和dirty,由硬件负责管理,程序员不需要care
SV39虚拟地址转物理地址过程
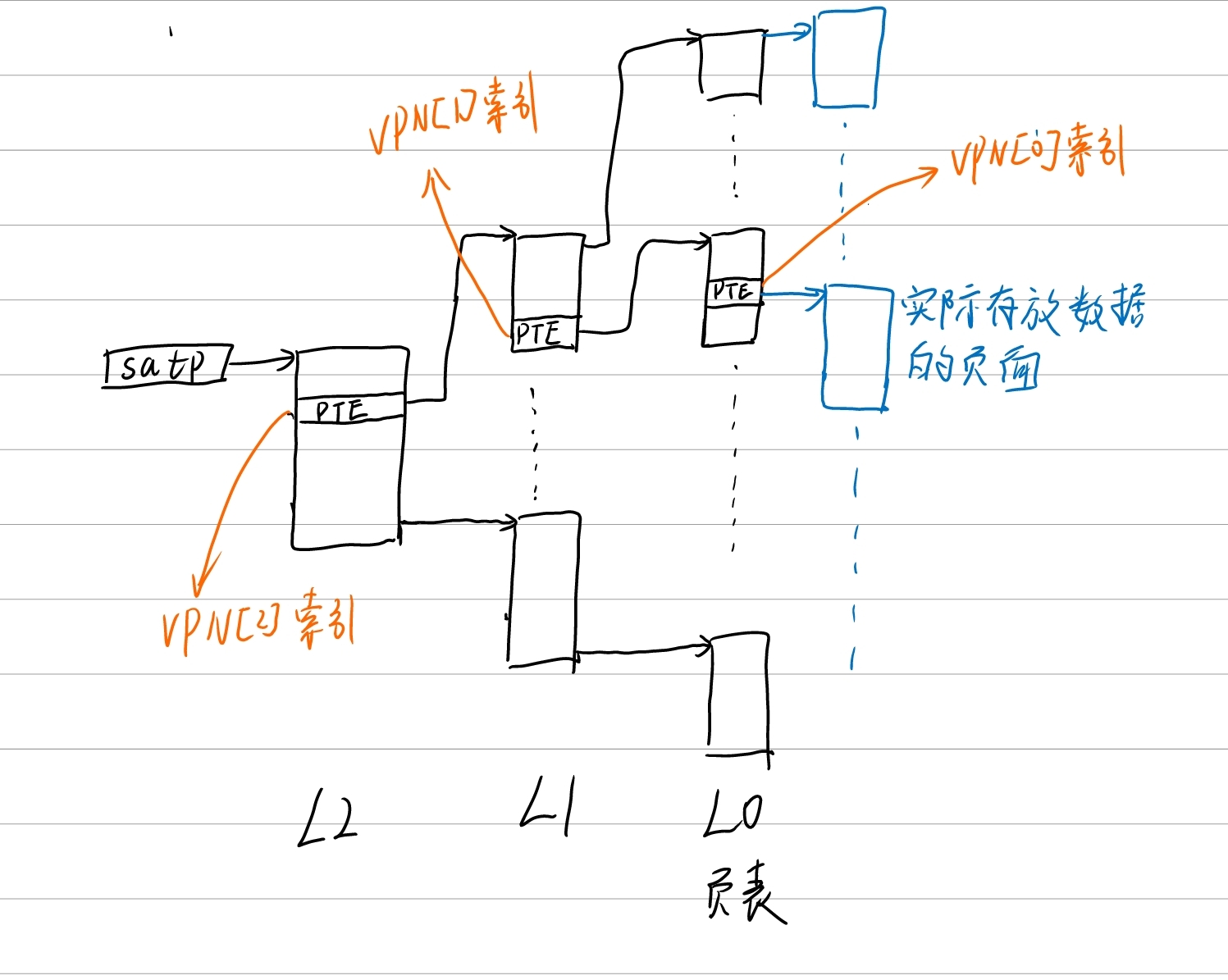
这里注意,我遵循x86的习惯对各级页表进行了命名,从satp寄存器指向的页表开始分别是L2, L1, L0,其中L0就是页表,页表中的每一项都是页表项,L2和L1实际是页目录表,页目录表中的每一项都是页目录项,在RISC v都称之为页表项。
satp寄存器保存的内容也可以认为是一个页表项,该PTE右移10bit就能获得PPN,PPN左移12bit就得到了L2页面的物理地址。
L2是root of page table,一个页面是4K大小,每个PTE是64bit(8byte),因此一个页目录表包含
L0和L1的索引过程与L2相同,不再赘述。
在L0中我们使用VPN[0]索引到了PTE,并根据PTE中的PPN获得了物理地址,但是我们知道一个页面是4KB,而CPU访存的最小单元是byte,因此还需要知道CPU要访问的具体是哪个byte,这就使用到了虚拟地址中的page offset。page offset占12bit,正好能够对一个物理页面进行byte级寻址。
大页技术
RISC v支持大页技术。我们前文说的,SV3级转换的每个PTE指向一个页面。当使用大页技术时,就没有了L0级,L1级的PTE指向2MB大小的连续物理内存;或者L0和L1级页表都不存在了,L2级的每个PTE直接指向1GB大小的连续物理内存。一般情况下只会使用到2MB的大页技术。
那么如何判定当前当前PTE是不是叶子PTE呢?当V=1且WXR不同时为0时,就说明当前的PTE是叶子节点。因此当检查到L1级的PTE是叶子PTE时,CPU就会认为当前是大页模式。
RISC v中断与异常
软件结构
keystone-enclave的实现分为四部分:secure monitor, sdk, keystone-driver, runtime。在介绍这四个部分之前
| 特权级 | 功能 | 实现 | |
|---|---|---|---|
| Secure monitor | M-MODE | 提供内存隔离能力 | Keystone SM is implemented as an experimental extension of OpenSBI. |
| SDK | U-MODE | sdk的代码编译为若干个静态库,编译host app时将下述静态库链接进去。libkeystone-host.alibkeystone-edge.alibkeystone-verifier.alibkeystone-eapp.a | |
| linux-keystone-driver | S-MODE | 提供enclave的创建、销毁、运行、恢复的功能 | |
| runtime | ES-MODE | eapp运行时,部分兼容posix,不支持多线程,因此eapp不能是多线程的程序 | 一个小型的OS内核,包括内存管理、中断服务等功能 |
基本运行过程
RICH OS到TEEOS的切换过程
- 开发者编写host app和eapp,使用RISC v的编译器进行编译,需要链接sdk相关静态库,需要按照sdk提供的example编写cmake以正确编译eyrie-rt(不需要开发者编写,keystone开发者已实现)
- 假设host app编译出的二进制程序名称为
runner,eapp编译出的二进制程序为eapp,编译出的运行时二进制文件名称为eyrie-rt,那么执行./runner eapp eyrie-rt就能正常运行,此时hart处于U-MODE - 用户在执行
./runner eapp eyrie-rt之后,runner会准备enclave环境。runner通过sdk封装好的函数与keystone linux driver进行沟通,以执行创建、运行、销毁enclave等操作。sdk封装的函数是通过ioctl与驱动建立联系的。第一步是通知Linux driver创建enclave,驱动会准备好相关环境。此时hart处于S-MODE - 之后Linux driver会通过
sbi_call与SM建立联系,调用sbi_call之后,hart处于M-MODE。如果要求SM创建enclave,SM会准备相关的环境。 sbi_call执行完毕后,会从M-MODE切换到S-MODE,就会返回到RICH OS的驱动中- 代码继续执行,如果是RICH OS就会继续从驱动中返回到U-MODE
runner通知运行enclave,通过ioctl陷入到S-MODE,执行驱动代码- 驱动通过
sbi_call陷入到M-MODE执行SM代码 - SM切换上下文,换出RICH OS的上下文,装入TEEOS的上下文
- SM从M-MODE返回到S-MODE,也就跳入了TEEOS中
TEEOS切换回RICH OS的过程
- eapp执行系统调用
- eyrie-rt会检查系统调用,如果需要切换回host app就调用
SBI_CALL(defined in eyrie/src/sbi.c) - SM就会切换上下文然后从M-MODE切换到S-MODE,此时由于切换了上下文就会转入RICH OS
编程模型
使用keystone enclave保护APP的关键数据和代码时,需要编写两个app,一个是host app,一个是eapp。其中host app运行在rich os,eapp运行在enclave中。这两个app在运行时都是独立的进程,因此在编程时都需要有相应的main函数。
编译与运行
以hello word为例,host和eapp的代码分别如下:
// host code
// 编译出的二进制文件名称为 hello-runner
// sdk/examples/hello/host/host.cpp
#include "edge/edge_call.h"
#include "host/keystone.h"
using namespace Keystone;
int
main(int argc, char** argv) {
Enclave enclave;
Params params;
params.setFreeMemSize(1024 * 1024);
params.setUntrustedMem(DEFAULT_UNTRUSTED_PTR, 1024 * 1024);
//这里传入的参数分别是eapp的二进制程序路径和runtime二进制文件的路径
enclave.init(argv[1], argv[2], params);
enclave.registerOcallDispatch(incoming_call_dispatch);
edge_call_init_internals(
(uintptr_t)enclave.getSharedBuffer(), enclave.getSharedBufferSize());
enclave.run();
return 0;
}
//eapp code
// 编译出的二进制名称为 hello
// sdk/examples/hello/eapp/hello.c
#include <stdio.h>
int main()
{
printf("hello, world!\n");
return 0;
}
在这种模式下,开发者只需要关注自己的业务逻辑,不需要关心enclave的创建、运行、销毁等问题。因为一个eapp的进程都在enclave里面。enclave的创建等都由host app负责。
在这个例子中,host code编译出的二进制文件是hello-runner,eapp编译出的二进制文件是hello,运行时的二进制文件是eyrie-rt(运行时代码是keystone的开发者提供的,如何编译出运行时请参考keystone代码提供的样例,在CMakeLists.txt中有详细的过程,在后文中我会进行介绍)。
在运行时,只需要执行./hello-runner hello eyrie-rt即可。
具体eapp究竟是怎么运行起来的,目前读者先不需要考虑,后文会详细介绍。
SDK overview
SDK包括四个组件:
| 组件 | 说明 | |
|---|---|---|
src/host |
host lib提供了一个接口,用于通过Enclave类管理enclave应用程序。无论运行时如何,这个库的大部分都可以正常工作 |
|
src/app |
Enclave application lib,提供简单的 enclave 工具(EXIT 等)以及一些基本的 libc 风格的函数(malloc、string header等) | |
src/edge |
为eapps 和主机提供管理边缘调用的功能。边缘调用是跨越 enclave-host 边界的函数调用。目前我们只支持来自enclave->host 的调用。您可以通过在此接口上进行轮询来模拟 host->enclave 调用。边缘库用在很多地方,包括运行时以及主机和 eapp 库。 |
|
src/verifier |
远程证明的库 | |
其中src/edge的代码很简单,但是过程却是复杂的,我将放到最后再讲。 |
SDK-host Lib Enclave分析

eapp的加载过程
以sdk/examples/hello为例进行分析。在host/hello.c中,给出了一个enclave创建和与运行的实例过程。首先要声明一个Enclave enclave,调用enclave.init函数初始化enclave,调用enclave.run()运行enclave。在源码中还有enclave.registerOcallDispatch等过程,将在后文中介绍。
Enclave init
Enclave::init()函数定义在sdk/src/host/Enclave.cpp中,其函数原型为:
Error
Enclave::init(
const char* eapppath, const char* runtimepath, Params _params,
uintptr_t alternatePhysAddr);
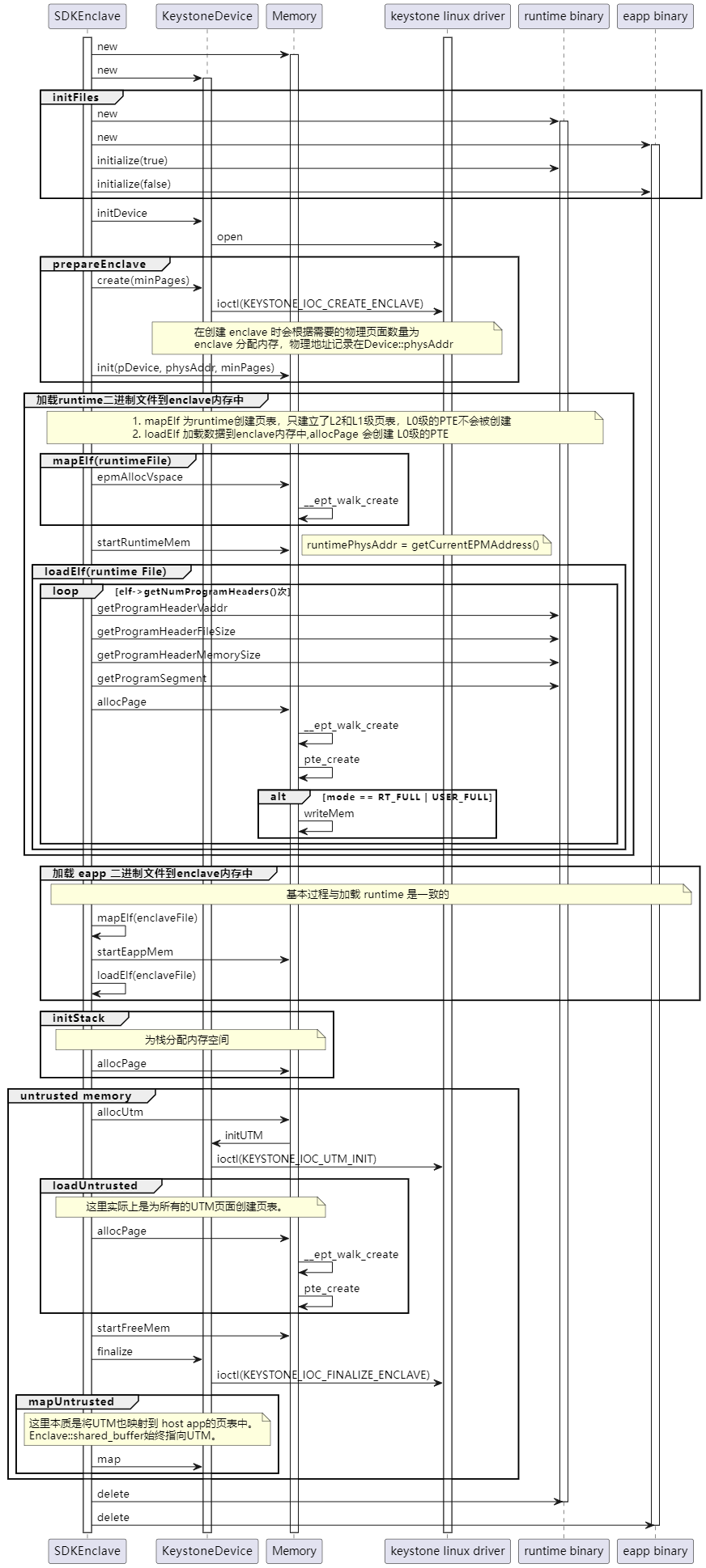
这里我们暂时不考虑alternatePhysAddr参数,该参数的默认值为0。enclave.init(argv[1], argv[2], params)调用了该init函数,以./hello-runner hello eyrie-rt的执行命令为例,我们可知eapppath就是hello,runtimepath就是eyrie-rt。这里会涉及内存管理和keystone驱动方面的问题,大家暂时忽略,后文会详细介绍内存管理。下面结合源码进行分析:
*Error*
*Enclave::init(*
*const char* eapppath, const char* runtimepath, Params _params,*
*uintptr_t alternatePhysAddr) {*
*params = _params;*
*//首先判断是否是模拟器模式,我们这里不分析模拟器的情况*
*if (params.isSimulated()) {*
*pMemory = new SimulatedEnclaveMemory();*
*pDevice = new MockKeystoneDevice();*
*} else {*
*pMemory = new PhysicalEnclaveMemory();*
*pDevice = new KeystoneDevice();*
*}*
**
*//init函数会调用Enclave::initFiles()加载eapp和运行时的二进制文件*
*//二进制文件的内容会的首地址保存在 ElfFile::ptr 中*
*//在initFiles函数中会创建两个ElfFile类的实例,分别表示eapp和运行时的二进制文件*
*// ElfFile类负责对elf二进制文件的分析,实际上只是分析了elf header*
*// 但是将二进制文件的所有内容都mmap到了 ElfFile::ptr 中*
*if (!initFiles(eapppath, runtimepath)) {*
*return Error::FileInitFailure;*
*}*
**
*// 建立与驱动的连接。*
*if (!pDevice->initDevice(params)) {*
*destroy();*
*return Error::DeviceInitFailure;*
*}*
*// 为enclave准备内存,该函数内部会计算需要准备多少内存*
*// 需要的内存数量是 enclaveFile 和 runtimeFile 的文件大小的总和*
*// + 为创建页表需要占用的物理内存空间(15个页面)*
// + freemem size
// freemem size的大小在host app中设置: params.setFreeMemSize(1024 * 1024);
*// 然后通知驱动创建内存*
// + free memory 需要的页面
// 由于 v1.0.0 的代码已经支持 USE_FREEMEM ,因此还需留足free memory
// 后面在 runtime 章节会详细讲解 USE_FREEMEM
*// prepareEnclave 也会初始化 pMemory*
*// pMemory->startAddr = phys_addr 就会保存驱动分配的物理内存的物理首地址,注意不是虚拟地址,是物理地址*
*// pMemory->epFreeList = phys_addr + PAGE_SIZE*
*// pMemory->rootPageTable = allocMem(PAGE_SIZE)*
// allocMem() 实际上调用的是 mmap,在 fd 上面映射了一个页面大小的内存空间
// 这里 mmap 实际上映射的就是 phys_addr 的第一个页面
// 因此 pMemory->rootPageTable 此时就是指向驱动分配的物理内存的虚拟地址
if (!prepareEnclave(alternatePhysAddr)) {
destroy();
return Error::DeviceError;
}
// 内部会调用 pMemory->epmAllocVspace() -> __ept_walk_create 函数
// 会根据 elf 的起始地址和所需大小分配虚拟内存空间
// 分配虚拟内存空间时会自动为创建页表,这里只是建立了页表,实际的内存并没有分配
// 因此最后一级的页表项并未建立
if (!mapElf(runtimeFile)) {
destroy();
return Error::VSpaceAllocationFailure;
}
// 实际执行的就是 「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「」「pMemory->runtimePhysAddr = pMemory->epmFreeList
// epmFreeList 在 pMemory->epmAllocVspace() --> __ept_walk_create -->
// __ept_walk_internal --> __ept_continue_walk_create
// 这个函数调用链中的最后一层被修改,每次 + PAGE_SIZE
// 因此 epmFreeList 此时实际上就是指向的 mapElf() 之后已消耗的物理页面的下一个页面的首地址
// 在后文中会使用 loadElf 加载 runtimeFile,因此 pMemory->runtimePhysAddr
// 也就是指向了 runtime 的物理地址的首地址
pMemory->startRuntimeMem();
// loadElf -> pMemory-allocPage -> __ept_walk_create
// 这里会紧接着
if (loadElf(runtimeFile) != Error::Success) {
ERROR("failed to load runtime ELF");
destroy();
return Error::ELFLoadFailure;
}
if (!mapElf(enclaveFile)) {
destroy();
return Error::VSpaceAllocationFailure;
}
pMemory->startEappMem();
// 在上文的 mapElf 中我们创建了页表,在 loadElf 中会根据 ELF 将代码、数据等加载到对应的虚拟地址空间中
// loadElf 通过 pMemory->allocPage() 为虚拟地址空间分配了页面,创建了页表项
if (loadElf(enclaveFile) != Error::Success) {
ERROR("failed to load enclave ELF");
destroy();
return Error::ELFLoadFailure;
}
/* initialize stack. If not using freemem */
// 在 v1.0.0 的代码中, USE_FREEMEM 已经被定义,因此这里的代码不会被执行
// 后面在介绍 runtime 的编译时会解释 USE_FREEMEM 宏是怎么被定义的
#ifndef USE_FREEMEM
if (!initStack(DEFAULT_STACK_START, DEFAULT_STACK_SIZE, 0)) {
ERROR("failed to init static stack");
destroy();
return Error::PageAllocationFailure;
}
#endif /* USE_FREEMEM */
uintptr_t utm_free;
// 内部会调用 pDevice->initUTM() 通知驱动创建 UTM
utm_free = pMemory->allocUtm(params.getUntrustedSize());
if (!utm_free) {
ERROR("failed to init untrusted memory - ioctl() failed");
destroy();
return Error::DeviceError;
}
// 内部调用 pMemory->allocPage() 创建页表项并分配页面
if (loadUntrusted() != Error::Success) {
ERROR("failed to load untrusted");
}
struct runtime_params_t runtimeParams;
runtimeParams.runtime_entry =
reinterpret_cast<uintptr_t>(runtimeFile->getEntryPoint());
runtimeParams.user_entry =
reinterpret_cast<uintptr_t>(enclaveFile->getEntryPoint());
runtimeParams.untrusted_ptr =
reinterpret_cast<uintptr_t>(params.getUntrustedMem());
runtimeParams.untrusted_size =
reinterpret_cast<uintptr_t>(params.getUntrustedSize());
pMemory->startFreeMem();
/* TODO: This should be invoked with some other function e.g., measure() */
if (params.isSimulated()) {
validate_and_hash_enclave(runtimeParams);
}
// 通知驱动执行 finalize 操作
if (pDevice->finalize(
pMemory->getRuntimePhysAddr(), pMemory->getEappPhysAddr(),
pMemory->getFreePhysAddr(), runtimeParams) != Error::Success) {
destroy();
return Error::DeviceError;
}
// 内部调用 pDevice->map(0, size)
if (!mapUntrusted(params.getUntrustedSize())) {
ERROR(
"failed to finalize enclave - cannot obtain the untrusted buffer "
"pointer \n");
destroy();
return Error::DeviceMemoryMapError;
}
//}
/* ELF files are no longer needed */
delete enclaveFile;
delete runtimeFile;
enclaveFile = NULL;
runtimeFile = NULL;
return Error::Success;
}
eapp的运行
Error
Enclave::run(uintptr_t* retval) {
if (params.isSimulated()) {
return Error::Success;
}
// 运行eapp,eapp的返回值存储在retval中,后文会详细分析 run 的过程,这里读者只需要知道
// 调用了 run 函数之后,就会切换到 enclave 中运行了
// ret 保存的是run函数退出的原因,也即是 enclave 退出的原因
// 注意 enclave 退出不一定就是运行完成了,可能只是由于 edge call 或者 中断等原因临时退出
// 之后还需要 resume
Error ret = pDevice->run(retval);
// 假如说run函数退出的原因是 eapp 主动调用 host 端的函数或者是 eapp 发生了中断
// 那么就需要在处理完中断或者执行完 host 端的代码之后恢复 eapp 的执行
while (ret == Error::EdgeCallHost || ret == Error::EnclaveInterrupted) {
/* enclave is stopped in the middle. */
if (ret == Error::EdgeCallHost && oFuncDispatch != NULL) {
// 如果是需要调用 host 端的函数那么就调用
// oFuncDispatch 是一个函数指针,是在 Enclave::registerOcallDispatch(OcallFunc func)
// 中被设置的
oFuncDispatch(getSharedBuffer());
}
// 恢复 eapp 的执行
ret = pDevice->resume(retval);
}
if (ret != Error::Success) {
ERROR("failed to run enclave - ioctl() failed");
destroy();
return Error::DeviceError;
}
return Error::Success;
}
SDK-host Lib 内存管理
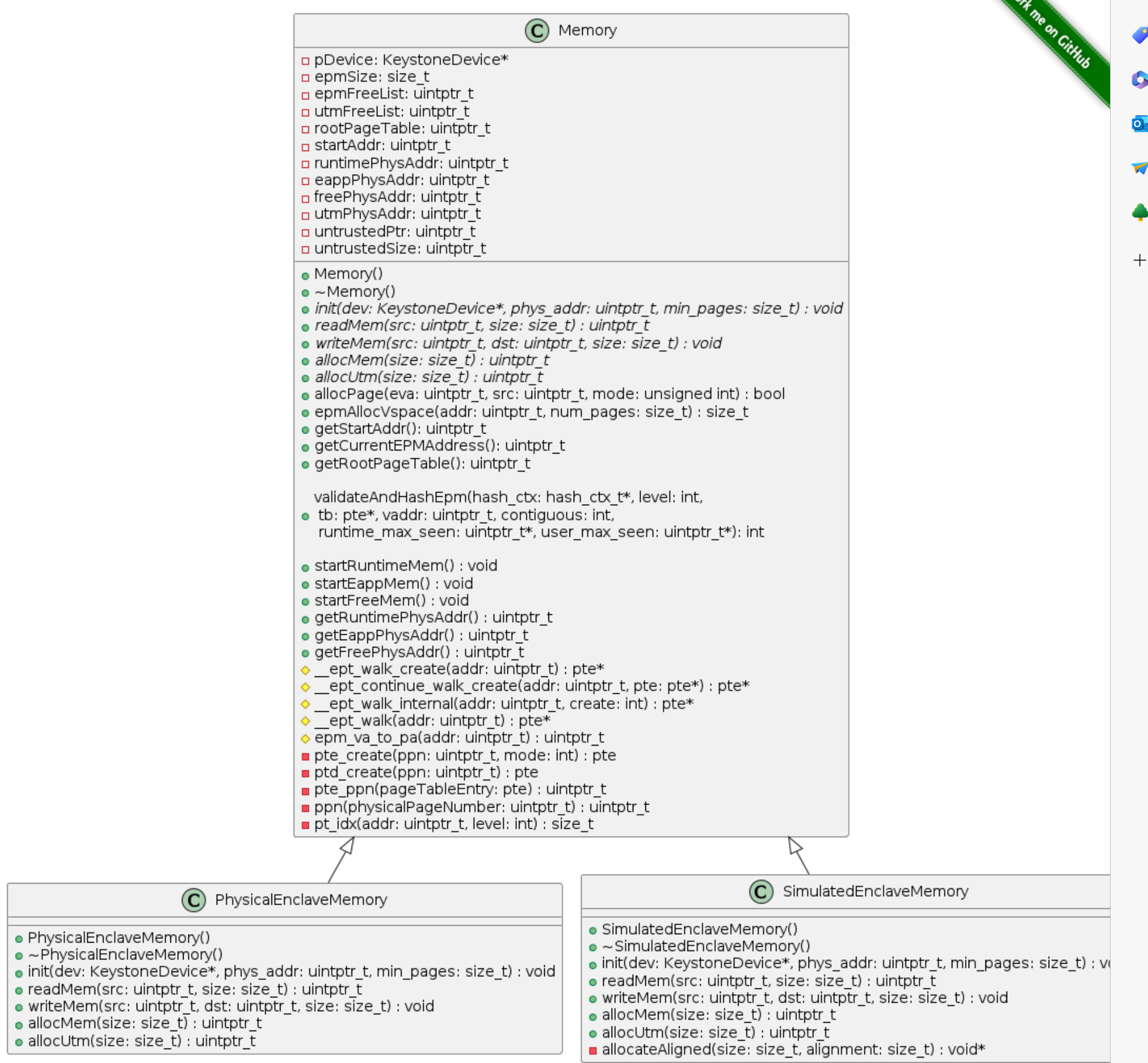
sdk内存管理的核心是为enclave创建页表、将enclave所需的二进制文件加载到enclave内存。
SDK内存管理相关的类
页表项查询过程
页表项查询是__ept_walk_internal()函数实现的,该函数的原型是:
pte*
Memory::__ept_walk_internal(uintptr_t addr, int create);
addr是需要查询的虚拟地址,当页表存在时,就会返回addr所在物理页面对应的PTE的虚拟地址,即是指向L0级页表中的PTE的虚拟地址。这里可能有些绕,我们知道L0级页表中的数据就是ptr。*ptr就是该PTE的值。
create指示是否在发现addr的各级页表项不存在时进行创建,我们这里只考虑查询过程,因此可以默认create = 0.
下面对源码进行剖析。
pte* t = reinterpret_cast<pte*>(rootPageTable);
rootPageTable是虚拟地址,指向的是驱动创建的用于保存enclave页表、runtime代码和数据、eapp代码和数据的连续物理内存。
// #define VA_BITS 39 // sv39, 有效虚拟地址长度为39bit
// #define RISCV_PGSHIFT 12 // ppn 为 12bit
// #define RISCV_PGLEVEL_BITS 9 // 每个 vpn 为 9bit
// 这里的循环就是 i 为 2 或者 1 的时候执行循环体里的内容
for (i = (VA_BITS - RISCV_PGSHIFT) / RISCV_PGLEVEL_BITS - 1; i > 0; i--) {
size_t idx = pt_idx(addr, i);//获取 vpn[i] vpn就是 virtual page number
// 判断 当前 pte 是否存在,如果不存在的话就判断 create 是否为 true
// 如果需要创建则递归创建页表
// 如果不需要创建,那么就返回 0,因为页表不存在嘛,所以也就找不到
if (!(pte_val(t[idx]) & PTE_V)) {
return create ? __ept_continue_walk_create(addr, &t[idx]) : 0;
}
// pte_ppn 实际上就是将 t[idx] 右移 10bit 获得物理地址的 ppn
// 再将ppn左移 12bit 就得到了物理地址
// 由于这里得到的是物理地址(物理内存是驱动分配的),因此需要转换为虚拟地址才能够为进程使用
// 因此这里调用了 readMem(),本质上就是执行了 mmap 操作
// 当 i == 2 时,此时 t 就是指向 L1级页表的 PTE
// 当 i == 1 时,此时 t 就是指向 L0级页表的PTE
// 由于 i 是 从 2 循环到 1, 因此循环退出时,t 是 L1级页表中的PTE,指向 L0级页表
t = reinterpret_cast<pte*>(readMem(
reinterpret_cast<uintptr_t>(pte_ppn(t[idx]) << RISCV_PGSHIFT),
PAGE_SIZE));
}
/*
* 当 level == 2 时,取得的是vpn[2]
* 当 level == 1 时,取得的是vpn[1]
* 当 level == 0 时,取得的是vpn[0]
*/
size_t
Memory::pt_idx(uintptr_t addr, int level) {
size_t idx = addr >> (RISCV_PGLEVEL_BITS * level + RISCV_PGSHIFT);
return idx & ((1 << RISCV_PGLEVEL_BITS) - 1);
}
// 在对 for 循环的分析中我们已经知道,此时 t 是L1级页表中的PTE
// 这里再次进行索引得到的就是 L0级页表的PTE
// 返回时取地址,那么返回值就是 L0 级页表中的某个 PTE 的虚拟地址
return &t[pt_idx(addr, 0)];
页表构建过程
在Memory类中,public属性的函数中,只有allocPage()和epmAllocVspace()在内部调用了创建页表的函数__ept_walk_create()。__ept_walk_create()实际调用了__ept_walk_internal()进行页表的创建,该函数本质上是一个页表项查询的函数,当然在查询过程可以在发现相应页表项不存在时进行创建。
在上文中我们已经分析了页表的查询过程,下面我们来分析创建过程。
/*
* 该函数是实际创建页表的地方,首先会获取当前空闲物理页的物理地址的ppn,
* 然后根据ppn创建一个pte
* 空闲的物理内存地址 + PAGE_SIZE,因为要创建一个PTE,
* 该PTE一定指向一个物理页面,因此空闲的物理页面就会减少一个
* 之后调用 __ept_walk_create
* __ept_walk_create 会从 L2 开始查询PTE,因为第一次查询L2时发现缺失了该PTE已经新建了一个,
* 因此再次查找是L2中就不会缺失PTE,那么就会在 L1中查找PTE,如果L1中的PTE缺失的话
* 就会继续调用 __ept_continue_walk_create 进行创建,然后重新调用__ept_walk_create
* 再次从头开始查询 PTE
* 这个过程会重复进行,直到所有的PTE都已经成功创建了。
*/
pte*
Memory::__ept_continue_walk_create(uintptr_t addr, pte* pte) {
uint64_t free_ppn = ppn(epmFreeList);
*pte = ptd_create(free_ppn);
epmFreeList += PAGE_SIZE;
return __ept_walk_create(addr);
}
pte*
Memory::__ept_walk_internal(uintptr_t addr, int create) {
pte* t = reinterpret_cast<pte*>(rootPageTable);
int i;
for (i = (VA_BITS - RISCV_PGSHIFT) / RISCV_PGLEVEL_BITS - 1; i > 0; i--) {
size_t idx = pt_idx(addr, i);
// 判断 当前 pte 是否存在,如果不存在的话就判断 create 是否为 true
// 如果需要创建则递归创建页表
// 如果不需要创建,那么就返回 0,因为页表不存在嘛,所以也就找不到
if (!(pte_val(t[idx]) & PTE_V)) {
return create ? __ept_continue_walk_create(addr, &t[idx]) : 0;
}
t = reinterpret_cast<pte*>(readMem(
reinterpret_cast<uintptr_t>(pte_ppn(t[idx]) << RISCV_PGSHIFT),
PAGE_SIZE));
}
return &t[pt_idx(addr, 0)];
}
enclave内存的创建与页表的建立
enclave物理内存空间布局
enclave内存的创建与页表的建立是在host端完成的。具体的说,是在Enclave::intinit(函数进行分析。
Enclave::initprepareEnclave(函数,在prepareEnclave函数中,会计算runtime和eapp所需的最小内存并通知驱动创建enclave内存。enclave内存是由驱动创建的一段连续的物理内存空间。- enclave内存创建完成之后,会通过
mapElf创建页表,loadElf加载相应的二进制文件到enclav内存中。
enclave虚拟内存空间布局
在前文我们看到runtime和eapp是公用页表的,因此二者在同一个虚拟内存空间中。我们仍然以examples/hello为例,看一下虚拟内存空间布局。我们使用readelf工具查看Program Header.
首先我们要明确的是,这里的虚拟内存布局并不是enclave运行起来之后的虚拟内存布局,在runtime的eyrie_boot()中会重新建立页表,虚拟内存布局也会有所改变。
eapp的虚拟内存空间布局
readelf -lW hello执行结果如下,可以看出Type为LOAD的两个段分别需要加载到虚拟地址的0x0000000000010000,0x0000000000069488。读者可能疑惑PhysAddr字段,但是这个字段实际上没啥用,具体加载到物理内存的哪里是由加载器控制的。
Elf file type is EXEC (Executable file)
Entry point 0x10518
There are 7 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOPROC+0x3 0x05e205 0x0000000000000000 0x0000000000000000 0x000042 0x000000 R 0x1
LOAD 0x000000 0x0000000000010000 0x0000000000010000 0x058dae 0x058dae R E 0x1000
LOAD 0x059488 0x0000000000069488 0x0000000000069488 0x004d50 0x00a1f0 RW 0x1000
NOTE 0x0001c8 0x00000000000101c8 0x00000000000101c8 0x000020 0x000020 R 0x4
TLS 0x059488 0x0000000000069488 0x0000000000069488 0x000018 0x000058 R 0x8
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
GNU_RELRO 0x059488 0x0000000000069488 0x0000000000069488 0x002b78 0x002b78 R 0x1
Section to Segment mapping:
Segment Sections...
00 .riscv.attributes
01 .note.ABI-tag .rela.dyn .text __libc_freeres_fn .rodata .eh_frame .gcc_except_table
02 .tdata .preinit_array .init_array .fini_array .data.rel.ro .data __libc_subfreeres __libc_IO_vtables .got .sdata .bss __libc_freeres_ptrs
03 .note.ABI-tag
04 .tdata .tbss
05
06 .tdata .preinit_array .init_array .fini_array .data.rel.ro
runtime的虚拟内存空间布局
readelf -lW eyrie-rt执行结果如下,可以看出Type为LOAD的段需要加载到虚拟地址的0xffffffffc0000000。
Elf file type is EXEC (Executable file)
Entry point 0xffffffffc0000000
There are 3 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOPROC+0x3 0x006930 0x0000000000000000 0x0000000000000000 0x000042 0x000000 R 0x1
LOAD 0x001000 0xffffffffc0000000 0xffffffffc0000000 0x005930 0x018000 RWE 0x1000
GNU_STACK 0x000000 0x0000000000000000 0x0000000000000000 0x000000 0x000000 RW 0x10
Section to Segment mapping:
Segment Sections...
00 .riscv.attributes
01 .text .fixup .rodata __ex_table .data .got .got.plt .bss .sbss .kernel_stack
02
在Enclave::init()中还调用了initStack()为栈空间建立页表(注意同时分配了物理内存),stack的虚拟内存起始地址是0x0000000040000000,stack的大小是1024 * 16(4个页面)。
UTM的虚拟内存空间布局
在源码中有params.setUntrustedMem(DEFAULT_UNTRUSTED_PTR, 1024 * 1024);这里设置了UTM的起始地址和大小。
因此,整个enclave的虚拟地址空间是(值得注意的是freemem的页表并没有建立,在分析runtime的eyrie_boot中才会知道freemem的虚拟地址):
Keystone Linux driver
Keystone driver为host app提供了六个功能,可以分为两大类:连续物理内存管理、与SM沟通的桥梁。这两类并不是非此即彼的,比如KEYSTONE_IOC_DESTROY_ENCLAVE功能就提供了物理内存管理,而且会跟SM进行通信。
SDK调用驱动相关功能的方法是使用ioctl()系统调用。
ioctl通信机制
亲爱的,请你去查一下吧,不想大篇幅的阐述了。这里仅简要介绍ioctl的作用。
驱动在keystone_user.h定义了驱动与用户态进程通信的功能号、数据结构。用户态进程可以通过功能号要求驱动提供相应的功能,数据结构规范了二者通信的数据接口。当用户态进程希望使用驱动提供的功能时,就会调用ioctl()这个系统调用。以创建enclave为例,用户态进程执行ioctl(fd, KEYSTONE_IOC_CREATE_ENCLAVE, &encl),此时执行流就会陷入到内核态,Linux会处理一系列查找驱动提供的对应函数的过程,最终会找到keystone driver中的keystone_ioctl函数,在该函数中会根据提供的功能号调用不同的函数处理请求。值得注意的是,驱动不能直接访问用户态提供的参数,必须调用copy_from_user()函数将数据拷贝到内核中。为啥呢?当然是因为用户进程和内核处于不同的虚拟地址空间啦,你直接通过用户进程提供的虚拟地址访问数据当然会出错啦。
驱动通过ioctl机制对外提供的功能有:
| 功能 | 说明 | 连续物理内存管理 | 与SM进行沟通 |
|---|---|---|---|
| KEYSTONE_IOC_CREATE_ENCLAVE | 创建enclave内存,分配EID(enclave ID,每个enclave都有独一无二的ID) | YES | NO |
| KEYSTONE_IOC_FINALIZE_ENCLAVE | 收尾enclave的初始化,通知SM创建enclave | NO | YES |
| KEYSTONE_IOC_DESTROY_ENCLAVE | 通知SM销毁enclave回收分配给enclave的内存回收分配给enclave的ID号 | YES | YES |
| KEYSTONE_IOC_RUN_ENCLAVE | 通知SM运行enclave | NO | YES |
| KEYSTONE_IOC_RESUME_ENCLAVE | 通知SM恢复enclave的运行 | NO | YES |
| KEYSTONE_IOC_UTM_INIT | 为UTM分配连续的物理内存 | YES | NO |
物理内存分配
首先我们看连续物理内存分配,在SDK的Enclave::init()函数中,创建了enclave内存和untrusted内存。前者是用来装载runtime和eapp的二进制文件的,后者用于eapp和host app之间的通信。
为什么必须让驱动分配内存?
那么读者可能有疑问,为啥一定要让驱动分配内存呢?不能使用malloc函数呢?最直接的回答就是malloc()不能分配连续的物理内存,只能分配连续的虚拟内存。
那为什么一定要连续的物理内存呢?
首先对于enclave内存,我们需要使用PMP对其进行隔离,而PMP只能隔离连续的物理内存区域。其次是UTM,使用连续物理内存是因为我们需要将UTM映射到host app和eapp的虚拟内存空间中。读者或许会有疑问,直接使用mmap机制就可以同时实现两个进程之间的内存共享了,为啥一定要先分配一块连续的物理内存然后再映射到eapp和host app中呢?这里有两点原因,第一runtime并没有提供mmap的接口,必须要在初始化enclave时将UTM写入到enclave页表中;第二即使runtime提供了mmap接口,由于runtime和Linux内核处在不同的虚拟地址空间,也没办法实现host app和eapp的地址共享。因为mmap()只能分配连续的虚拟内存空间,Linux内核之所以能够实现在两个进程之间使用mmap()进行内存共享是因为Linux能够同时两个进程的映射的物理内存。runtime只能看到eapp映射的物理内存,看不到host app映射的物理内存。
驱动为enclave和UTM分配内存
首先是enclave内存的分配,SDK通过ioctl()函数通知驱动创建enclave时,驱动会首先调用keystone_ioctl(),在该函数中会根据用户态提供的信息分发到不同的处理函数,这里会分发给keystone_create_enclave();之后,会在keystone_create_enclave函数中调用create_enclave()函数,在这里我们看到驱动调用了kmalloc()函数为enclave->epm分配内存,之后调用了epm_init()函数,在该函数中最终调用了__get_free_pages()函数为enclave分配物理内存。
其次是UTM内存的分配。驱动首先执行keystone_ioctl(),调用utm_init_ioctl函数。在utm_init_ioctl函数中,驱动使用kmalloc()函数为struct utm;分配了内存,之后在utm_init()中调用了__get_free_pages()函数为UTM分配了内存。
再啰嗦一点,kmalloc()用于小内存分配,__get_free_pages()可分配大内存,因此使用了两种不同的接口。
与SM的沟通桥梁
驱动的第二个主要功能就是建立host app与SM的沟通渠道。这个过程就是host app调用ioctl()函数与驱动进行沟通,驱动通过调用sbi_call函数与SM进行沟通。
源码分析
驱动代码实在是短小精悍,而且没有太过难以理解的地方,读者自己看吧,我要是滔滔不绝的介绍这些代码,实在是太不知趣了。Talk is cheap, show me the code.
Runtime
runtime为eapp提供了必要的运行时需要的服务,如中断服务、系统调用、内存管理等,可以将runtime视为一个微型的OS,我们称之为TEEOS。
在本章节,我们会首先分析runtime的编译过程,因为在runtime中有很多的宏定义,我们首先得知道哪些宏定义是激活的。之后会介绍runtime各个section的内存布局,然后介绍enclave的内存布局。尽管我们在前文已经介绍过一次enclave的内存布局了,但是我们需要再次介绍,因为前文是SDK创建的enclave页表,而在runtime启动时会重新创建页表,其虚拟地址空间视图也有所变化。最后会介绍runtime的各个模块。
runtime的编译
runtime的编译会根据启用的plugin的不同而不同。在sdk/examples/tests/CMakeLists.txt和sdk/examples/hello-native/CMakeLists.txt中启用的plugin是freemem,在sdk/examples/hello/CMakeLists.txt中启用的是freemem untrusted_io_syscall linux_syscall env_setup,那么就会导致runtime编译时的选项有所不同。
在runtime/test/CMakeLists.txt中启用的宏定义有:
runtime的编译脚本如下所示,根据CMakeLists.txt启用的plugin,脚本会激活对应的宏。此外,在编译runtime时,会根据这些宏编译SDK,因此前文中提到的在Enclave::intiinti()并不会执行initStack(。
#!/bin/bash
EYRIE_SOURCE_DIR=`dirname $0`
REQ_PLUGINS=${@:1}
OPTIONS_LOG=${EYRIE_SOURCE_DIR}/.options_log
BITS="64"
# Build known plugins
declare -A PLUGINS
PLUGINS[freemem]="-DUSE_FREEMEM "
PLUGINS[untrusted_io_syscall]="-DIO_SYSCALL_WRAPPING "
PLUGINS[linux_syscall]="-DLINUX_SYSCALL_WRAPPING "
PLUGINS[env_setup]="-DENV_SETUP "
PLUGINS[strace_debug]="-DINTERNAL_STRACE "
PLUGINS[paging]="-DUSE_PAGING -DUSE_FREEMEM "
PLUGINS[page_crypto]="-DPAGE_CRYPTO "
PLUGINS[page_hash]="-DPAGE_HASH "
PLUGINS[debug]="-DDEBUG "
#PLUGINS[dynamic_resizing]="-DDYN_ALLOCATION "
OPTIONS_FLAGS=
echo > $OPTIONS_LOG
for plugin in $REQ_PLUGINS; do
if [ $plugin == 'rv32' ]; then
BITS="32"
elif [[ ! ${PLUGINS[$plugin]+_} ]]; then
echo "Unknown Eyrie plugin '$plugin'. Skipping"
else
OPTIONS_FLAGS+=${PLUGINS[$plugin]}
echo -n "$plugin " >> $OPTIONS_LOG
fi
done
export BITS
export OPTIONS_FLAGS
make -C $EYRIE_SOURCE_DIR clean
make -C $EYRIE_SOURCE_DIR V=1
runtime内存布局
runtime在链接阶段会根据runtime.lds文件设置各个节的内存布局。
- .text节:代表程序的代码段,用于存放可执行代码。该节起始地址为0xffffffffc0000000,使用PROVIDE指令定义了rt_base标记来表示该节的起始地址。在该节中有三个符号被定义:.text._start、.text.encl_trap_handler和.text,分别用于存放程序的入口点、陷阱处理函数(encl_trap_handler)和其他代码段。
- .rodata节:代表只读数据段,用于存放程序使用但不需要修改的常量数据。这里使用了两个符号:.rdata和.rodata,用于存放只读数据。紧跟在.text节后面,.rodata的起始地址会按照0x1000进行内存对齐。
- .data节:代表已初始化的数据段,用于存放程序中需要初始化赋值的全局变量和静态变量。
- .bss节:代表未初始化的数据段,用于存放全局变量和静态变量的未初始化空间。在实际运行时,该节的内容均会被初始化为零值。
- .kernel_stack节:代表内核栈。该节用于存放内核执行代码时使用的栈空间,并使用PROVIDE指令定义了kernel_stack_end标记来表示节的结束地址。.kernel_stack节的起始地址也是按照0x1000对齐,紧跟在.bss节的后面,栈大小是0x8000。
根据readelf -SW eyrie-rt绘制内存布局如下:
0xffffffc0000000 .text
0xffffffc0005948 .fixup
0xffffffc0006000 .rodata
0xffffffc00067c8 __ex_table
0xffffffc0006a80 .data
0xffffffc0006b00 .got
0xffffffc0006ba0 .got.plt
0xffffffc0007000 .bss
0xffffffc0010048 .sbss
0xffffffc0011000 .kernel_stack
enclave内存布局
在后文讲解的eyrie_bootinit(中创建的页表的虚拟内存空间布局有很大的不同。之所以在这里就把新的enclave虚拟内存空间给出,是为了同学们更容易理解。关于新页表的建立过程将会在后文详细分析。
新页表存储在了哪里?使用的是什么分页机制?
在runtime/mm/vm.c中,定义了若干个数组:
// BIT(RISCV_PT_INDEX_BITS) 其实就是 1<<9,一个页面有1<<9个PTE
/* root page table */
pte root_page_table[BIT(RISCV_PT_INDEX_BITS)] __attribute__((aligned(RISCV_PAGE_SIZE)));
/* page tables for kernel remap */
pte kernel_l2_page_table[BIT(RISCV_PT_INDEX_BITS)] __attribute__((aligned(RISCV_PAGE_SIZE)));
pte kernel_l3_page_table[BIT(RISCV_PT_INDEX_BITS)] __attribute__((aligned(RISCV_PAGE_SIZE)));
/* page tables for loading physical memory */
pte load_l2_page_table[BIT(RISCV_PT_INDEX_BITS)] __attribute__((aligned(RISCV_PAGE_SIZE)));
pte load_l3_page_table[BIT(RISCV_PT_INDEX_BITS)] __attribute__((aligned(RISCV_PAGE_SIZE)));
新页表就在这些数组中。其中kernel_l2_page_table是用于映射runtime的,load_l2_page_table用于映射整个enclave物理内存的。在eyrie_boot()中在进行内存映射时实际使用的是2MB大页机制,因此kernel_l3_page_table和load_l3_page_table都没有用上。由于这些数组都是全局变量,因此其在eyrie-rt二进制文件中位于.bss段。
如下图所示是eyrie_boot()执行之后的物理内存空间与虚拟地址空间的映射关系,采用的是新页表的虚拟空间视图。(我真的很想吐槽,keystone enclave的内存映射跟屎一样,我真的搞不懂为什么,为什么runtime要重新创建页表,就是为了减少TLB missing?一个3MB的破runtime搞这么复杂的映射机制图的啥?重新创建页表就算了,为什么只是对runtime的内存空间进行了创建,UTM、eapp内存空间都不重新映射?为什么要在0xffffffff_00000000的位置映射整个enclave的物理内存空间,只映射free memory和旧页表的内存区域不行吗?你这样重复映射了runtime和eapp的内存区域真的没有问题吗?真的就,啊,神经病!)
重新映射之后,根页表就在root_page_table数组中,runtime变成了2MB大页映射,二级页表是kernel_l2_page_table;enclave的整个物理内存空间也采用2MB大页映射,二级页表是load_l2_page_table(由于整个enclave物理内存空间都映射到了0xffffffff_00000000,free memory自然也映射进去了);由于eapp和UTM没有重新构建页表,而是使用copy_root_page_table()函数将旧页表的根页表的页表项拷贝到了新的根页表中,因此eapp和UTM的依然是4KB页映射机制有三级页表,他们的二级页表和三级页表依然在旧页表中,也就是映射到了下图中蓝色的区域。
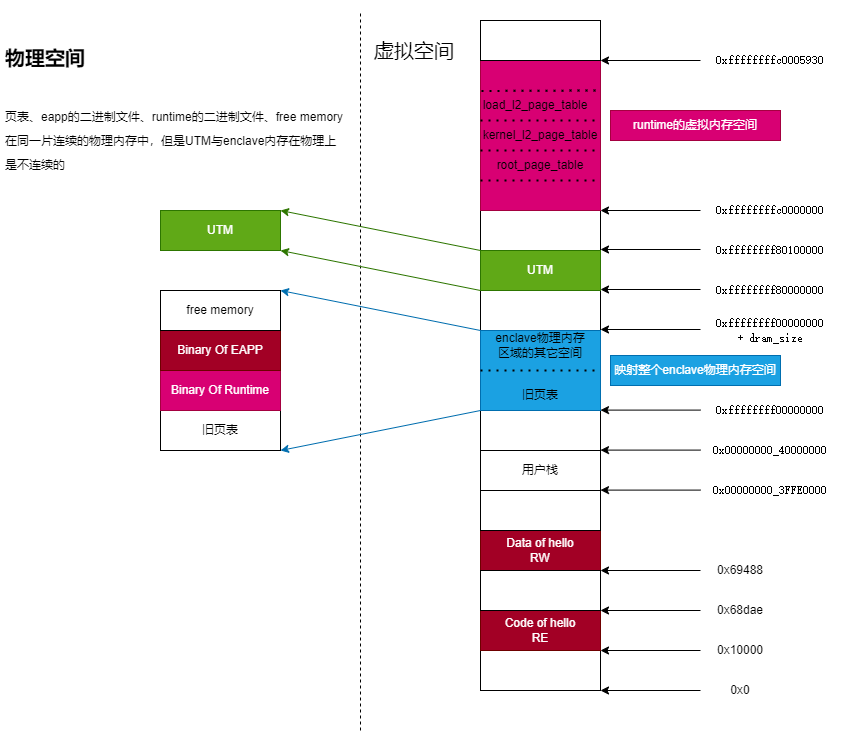
启动过程
SM为enclave的运行准备环境
当SM收到运行ENCLAVE的命令后,会在context_switch_to_enclave函数中准备好runtime的环境。尽管这个函数是SM中的,但是对于我们启动enclave至关重要,因此我们来分析一下该函数。对于很多东西我并没有完全解释,读者不必担心,后文在介绍SM时会再次解释的。读者只需要知道在这里给runtime的eyrie_boot()函数传入了七个参数即可。七个参数分别保存在a1~a7,a0用于保存SBI的返回值。
static inline void context_switch_to_enclave(struct sbi_trap_regs* regs,
enclave_id eid,
int load_parameters){
/* save host context */
swap_prev_state(&enclaves[eid].threads[0], regs, 1);
swap_prev_mepc(&enclaves[eid].threads[0], regs, regs->mepc);
swap_prev_mstatus(&enclaves[eid].threads[0], regs, regs->mstatus);
uintptr_t interrupts = 0;
csr_write(mideleg, interrupts);// 不把任何中断委托给 runtime
// 由于没有 修改 medeleg 的值,因此 runtime 与 Linux内核被委托了同样的异常
if(load_parameters) {
// passing parameters for a first run
// sepc 记录的是 eapp 的起始地址,在 runtime 的 _start 函数中会通过
// sret 指令跳转到 sepc 指向的地址开始执行
csr_write(sepc, (uintptr_t) enclaves[eid].params.user_entry);
// mepc 是 SM 执行 mret 之后要跳转到的地址
// 这里之所以减去4,是因为后续的SM的代码会自动将该变量加4
regs->mepc = (uintptr_t) enclaves[eid].params.runtime_entry - 4; // regs->mepc will be +4 before sbi_ecall_handler return
// mstatus 的 MPP 字段是 1 表示 之前的特权级是 S
// 关于 mstatus 的说明见 中断章节
regs->mstatus = (1 << MSTATUS_MPP_SHIFT);
// riscv 中 a0 到 a7 可以用作传递参数,可以使用寄存器传入八个参数
// 其中 a0 和 a1 是可以作为返回值
// 当 SM 执行 mret 返回S-mode时,a0 记录的就是 mret 的返回值
// 下面的七个参数其实就是给runtime的 eyrie_boot 函数传入的
// 尽管 eyrie_boot 有八个参数,但是由于 a0 保存的是 SBI 的返回值
// 因此实际可用的是 a1 到 a7 这七个参数
// $a1: (PA) DRAM base, enclave 物理地址的起始地址
regs->a1 = (uintptr_t) enclaves[eid].pa_params.dram_base;
// $a2: (PA) DRAM size, enclave 内存的大小
regs->a2 = (uintptr_t) enclaves[eid].pa_params.dram_size;
// $a3: (PA) kernel location, runtime的起始地址,物理地址
regs->a3 = (uintptr_t) enclaves[eid].pa_params.runtime_base;
// $a4: (PA) user location, eapp的起始地址,物理地址
regs->a4 = (uintptr_t) enclaves[eid].pa_params.user_base;
// $a5: (PA) freemem location, enclave中的空闲内存的起始物理地址
regs->a5 = (uintptr_t) enclaves[eid].pa_params.free_base;
// $a6: (VA) utm base, UTM的起始虚拟地址,注意是 enclave虚拟地址空间的虚拟地址
regs->a6 = (uintptr_t) enclaves[eid].params.untrusted_ptr;
// $a7: (size_t) utm size UTM 的大小
regs->a7 = (uintptr_t) enclaves[eid].params.untrusted_size;
// switch to the initial enclave page table
csr_write(satp, enclaves[eid].encl_satp);
}
switch_vector_enclave();
// set PMP
osm_pmp_set(PMP_NO_PERM);
int memid;
for(memid=0; memid < ENCLAVE_REGIONS_MAX; memid++) {
if(enclaves[eid].regions[memid].type != REGION_INVALID) {
pmp_set_keystone(enclaves[eid].regions[memid].pmp_rid, PMP_ALL_PERM);
}
}
// Setup any platform specific defenses
platform_switch_to_enclave(&(enclaves[eid]));
cpu_enter_enclave_context(eid);
}
eyrie_boot函数
好了,下面正式开始介绍runtime的启动。从SBI返回之后,就跳到了runtime的起始地址,runtime的起始地址在entry.S的_start。
_start:
// 设置栈地址,因为栈是从上往下开始生长的,因此加载的是 栈的最高地址
la sp, kernel_stack_end
// 下面的英文注释现在不理解没关系,后面会说明为啥将 sscratch 设置为0的
/* set sscratch zero so that the trap handler can
* notice that the trap is from S-mode */
csrw sscratch, x0
// 这里的 jal 指令实际上是伪指令, 实际的指令是 jal x1, offset
// 没错,伪指令和实际的指令是重名的
// jal x1, offset 的含义是跳转到 offset开始执行,并将当前指令的下一条指令保存到 x1 寄存器
// x1 的别名是 ra 寄存器
// eyrie_boot 函数编译后的指令 是 ret 或者 jr ra (二者是同一含义,都是无条件跳转到 ra指向的地址)
// 因此这里的含义起始就是 调用 eyrie_boot 函数
// call 这个伪指令跟 jal 差不多也是调用函数,但是 call 可以调用远距离的函数, jal 不行
jal eyrie_boot
/* start running enclave */
csrrw sp, sscratch, sp
// sret 指令会返回到 sepc 指向的地址
// sepc 寄存器值 是在 SM 的 context_switch_to_enclave 函数中设置的
// sepc 被 SM 设置成了 eapp 的起始地址
// 因此在 eyrie_boot 执行完毕后,执行 sret 会跳入到 eapp 开始执行
sret
下面分析eyrie_boot():
void
eyrie_boot(uintptr_t dummy, // $a0 contains the return value from the SBI
uintptr_t dram_base,//物理地址
uintptr_t dram_size,
uintptr_t runtime_paddr,//物理地址
uintptr_t user_paddr,//物理地址
uintptr_t free_paddr,//物理地址
uintptr_t utm_vaddr,//虚拟地址
uintptr_t utm_size)
{
/* set initial values */
load_pa_start = dram_base;
shared_buffer = utm_vaddr;
shared_buffer_size = utm_size;
// 0xffffffffc0000000, 自行查阅 runtime.lds, 我在前文也有介绍
runtime_va_start = (uintptr_t) &rt_base;
// 虚拟地址与物理地址偏移,用于 kernel_va_to_pa 和 kernel_pa_to_va
// 这是很显然地,由于虚拟内存地址和物理内存地址在分配时都是连续地
// va - kernel_offset 自然就可以得到对应地物理地址了
// va + kernel_offset
// 这里要牢记,后面会经常碰到 kernel_va_to_pa 和 kernel_pa_to_va
kernel_offset = runtime_va_start - runtime_paddr;
debug("UTM : 0x%lx-0x%lx (%u KB)", utm_vaddr, utm_vaddr+utm_size, utm_size/1024);
debug("DRAM: 0x%lx-0x%lx (%u KB)", dram_base, dram_base + dram_size, dram_size/1024);
#ifdef USE_FREEMEM
// #define EYRIE_LOAD_START 0xffffffff00000000
//static inline uintptr_t __va(uintptr_t pa)
//{
//return (pa - load_pa_start) + EYRIE_LOAD_START;
//}
// free_paddr 实际上 就在 eapp 的末尾
// 从 free_paddr 开始到 enclave 物理内存结束都是 free memory
// freemem_va_start = free_paddr - load_pa_start + EYRIE_LOAD_START
// 原因是,在后文的 map_physical_memory() 中,enclave的物理内存空间对应的虚拟地址空间的起始地址
// 就是 EYRIE_LOAD_START
freemem_va_start = __va(free_paddr);
freemem_size = dram_base + dram_size - free_paddr;
debug("FREE: 0x%lx-0x%lx (%u KB), va 0x%lx", free_paddr,
dram_base + dram_size, freemem_size/1024, freemem_va_start);
/* remap kernel VA */
// user_paddr - runtime_paddr 得到的就是 runtime_size ,具体参见前文的 enclave 物理内存布局章节
// remap_kernel_space 中会根据 dram_size 的大小确定映射方法
// 如果 dram_size > 2MB 那么就会启用大页分页模式,这样只有两级页表
// 否则就是三级页表分页
// 根页表是 root_page_table
// 此外,在Enclave::init() 中已经创建了页表了,为啥还要再次创建呢?
// remap_kernel_space 将runtime的物理地址空间映射到了以 runtime_va_start 开始的虚拟地址空间
// 二级页表项记录在 kernel_l2_page_table
remap_kernel_space(runtime_paddr, user_paddr - runtime_paddr);
// TODO
// 将整个enclave物理内存空间映射到页表中
// 根页表是 root_page_table
// 这里就很奇怪的代码,runtime 就在 enclave 物理内存空间中呀,映射物理内存空间
// enclave 的物理内存空间的起始虚拟地址是 EYRIE_LOAD_START,即 0xffffffff00000000
// 二级页表项记录在 load_l2_page_table
map_physical_memory(dram_base, dram_size);
/* switch to the new page table */
csr_write(satp, satp_new(kernel_va_to_pa(root_page_table)));
/* copy valid entries from the old page table */
// 这里只是把旧的根页表的有效项复制过来了
// 见后文的分析
copy_root_page_table();
/* initialize free memory */
// 把每个空闲页面的起始虚拟地址放在了 spa_free_pages 中
init_freemem();
//TODO: This should be set by walking the userspace vm and finding
//highest used addr. Instead we start partway through the anon space
//下面执行的结果就是 current_program_break = 0x0000_0020_4000_0000
set_program_break(EYRIE_ANON_REGION_START + (1024 * 1024 * 1024));
#ifdef USE_PAGING //未定义
init_paging(user_paddr, free_paddr);
#endif /* USE_PAGING */
#endif /* USE_FREEMEM */
/* initialize user stack */
// 在这个函数中为用户进程分配了0x20000B的栈空间
// USE_ENV_SETUP 宏没有被定义,不分析了就
init_user_stack_and_env();
// 这往下的内容就比较简单了,分别是设置 trap_handler,
/* set trap vector */
csr_write(stvec, &encl_trap_handler);
/* prepare edge & system calls */
// 实际上就是执行了
// _shared_start = buffer_start;
// _shared_len = buffer_len;
// 记录一下UTM的起始虚拟地址和大小 UTM 的二级页表和三级页表用的还是旧页表
init_edge_internals();
/* set timer */
init_timer();
/* Enable the FPU */
csr_write(sstatus, csr_read(sstatus) | 0x6000);
debug("eyrie boot finished. drop to the user land ...");
/* booting all finished, droping to the user land */
return;
}
eyrie_boot中的内存初始化
eyrie_boot中,使用remap_kernel_space()和map_physical_memory()重新建立了页表。其中remap_kernel_space()将runtime的二进制文件所占用的物理内存空间映射到了以runtime_va_start = 0xffffffffc0000000为起始虚拟地址的虚拟内存空间;其中map_physical_memory()是将enclave的整个物理内存空间映射到了以EYRIE_LOAD_START = 0xffffffff00000000为起始虚拟地址的虚拟内存空间。
之后,通过设置satp寄存器激活了页表。
在copy_root_page_table()中,将旧页表中L0级的根页表的有效项拷贝到了新页表中。这里我们要注意几个事项:
- 为什么旧页表的根地址是
EYRIE_LOAD_START?
我们通过将satp设置为新页表的根地址激活了新页表。在新页表中,我们将enclave的整个物理内存空间映射到了以EYRIE_LOAD_START为首的虚拟地址空间中。在Enclave::init()函数中,我们已经知道,旧页表处在enclave物理内存的最开始,因此旧页表的根地址对应的虚拟地址就是EYRIE_LOAD_START。(在已经激活分页的情况下的访存当然是要使用虚拟地址访问旧页表啦!)
- 拷贝了哪些内容?
通过分析函数可知,一共拷贝了1<<9个页表项,正好是一个页面的内容。也就是说,只把根页表的那一个页面的页表项拷贝到了新页表。
- 会不会覆盖新页表的有效项?
答案是不会。首先我们看新页表中已经有了哪些内容:EYRIE_LOAD_START = 0xffffffff00000000为首的虚拟内存空间和runtime_va_start = 0xffffffffc0000000为首的虚拟内存空间。 我们在Enclave::init()中创建的旧页表包含的是eapp的虚拟内存空间, runtime_va_start = 0xffffffffc0000000 为首的runtime的虚拟内存空间,以及以0xffffffff80000000首的UTM虚拟内存空间。其中以hello为例,eapp有两个段,分别是0x0000000000010000为首和0x0000000000069488为首的虚拟内存空间。而根页表中的一个页表项可覆盖的内存区域是
之后调用init_freemem()函数,将空闲的页面添加到spa_free_pages链表中。空闲页面的起始虚拟地址是freemem_va_start。
runtime的中断与异常处理
在runtime/call是runtime系统调用以及边缘调用的代码。io_wrap.c实现的是io相关的系统调用,net_wrap.c实现的是网络相关的系统调用,linux_wrap.c实现的是其它Linux系统调用,sbi.c封装的是ES-mode的runtime与M-mode的SM的通信接口,syscall.c实现的是runtime系统调用的入口函数以及边缘调用相关的代码。我们重点分析syscall.c,io_wrap.c中的若干函数,linux_wrap.c中的若干函数。net_wrap.c不分析,因为其实现过程与io_wrap.c几乎一致。
中断服务例程
在x86下,是通过int 0x80实现的用户态到内核态的特权级的切换。在RISC v中,是使用的ecall指令。ecall指令会触发一个异常,内核会捕获这个异常,CPU会跳入到stvec指向的中断服务例程。我们在eyrie_boot()中执行了csr_write(stvec, &encl_trap_handler);将stvec设置成了encl_trap_handler函数。(在Linux内核的U和S切换时,由于内核和进程使用不同的页表,需要切换页表,xv6-riscv和rCore都是通过trampoline实现的,笔者没有看过Linux内核的实现,但是相信原理上是一致的。由于keystone 的runtime和eapp公用页表,不需要切换页表,就省去了诸多麻烦)。
好了,现在我们知道用户态的程序在执行完ecall之后会跳入encl_trap_handler(defined in entry.S),现在看看这个函数吧。
该函数的作用是保存当前上下文并根据陷阱或异常的类型进行相应的处理。它首先将当前栈指针(sp)存储到sscratch寄存器中,并将新的栈指针值设为sp,然后检查之前的栈指针是否为零。如果不为零,则说明该陷阱或异常是来自内核态,需要恢复栈指针的值。接着,它保存了所有寄存器的值(除了栈指针),包括 sepc、sstatus、sbadaddr (根据最新的RISC v规范,sbadaddr已经更名为stval)和 scause 寄存器的值。然后,它根据scause中的值,判断是处理中断还是异常。如果scause的值小于零(这种判断是中断还是异常的方法是个很巧妙地实现,后文会解释),则表示该陷阱是由于一个异常引起的,函数将寻找一个叫做rt_trap_table的表,并根据这个表查找需要处理这个异常的处理函数,并通过JALR指令调用找到的函数。如果scause的值大于等于零,则表示该陷阱是由于一个中断引起的,函数将清除 MSB 位并跳转到称为handle_interrupts的函数。在处理完陷阱或异常之后,restore user stack恢复了之前保存的栈指针值,并且还将SSCRATCH寄存器的值设置为先前保存的栈指针,最后恢复所有寄存器的值(除了栈指针),并将栈指针重置为之前的值,用sret指令返回。
encl_trap_handler:
.global encl_trap_handler
/* TODO we may want to explicitly disable the FPU here ala linux */
// 交换 sp 和 sscratch 的值(留个任务吧,sscratch是在什么时候设置的初始值?)
csrrw sp, sscratch, sp
// 现在都是通过 sstatus 中的 SPP 来判断之前是处于哪个特权级
bnez sp, __save_context
/* if trap is from kernel, restore sp */
csrr sp, sscratch
__save_context:
/* save previous context */
SAVE_ALL_BUT_SP
csrrw t0, sscratch, x0 # t0 <- previous sp
STORE t0, 2*REGBYTES(sp) # previous sp
csrr t0, sepc
STORE t0, (sp)
csrr t0, sstatus
STORE t0, 32*REGBYTES(sp)
// sbadaddr 已经更名为了 stval
csrr t0, sbadaddr
STORE t0, 33*REGBYTES(sp)
csrr s2, scause
// 因为 scause 的最高位为1的话表示是中断,为 0 的话表示是异常
// 因此如果 scause > 0的话,那就是异常
bge s2, zero, 1f
/* handle interrupts */
/* clear the MSB */
//中断的 scause 的最高位为1,当把最高位clear之后,scause就是中断原因了
slli s2, s2, 1
srli s2, s2, 1
STORE s2, 34*REGBYTES(sp)
/* clear enclave context */
// 把所有的寄存器清零
CLEAR_ALL_BUT_SP
mv a0, sp
la t0, handle_interrupts
jalr t0
j return_to_encl
1:
/* handle exceptions */
STORE s2, 34*REGBYTES(sp)
la t0, rt_trap_table
sll t1, s2, LOG_REGBYTES
add t1, t0, t1
LOAD t1, 0(t1)
mv a0, sp
jalr t1
return_to_encl:
// 在返回之前是要激活 sstatus.SIE的,是不是很疑惑?
// 我将会在Enable SSTATUS.SIE章节讨论这个问题
LOAD t0, (sp)
csrw sepc, t0
// restore user stack
LOAD t0, 2*REGBYTES(sp)
csrw sscratch, t0
RESTORE_ALL_BUT_SP
csrrw sp, sscratch, sp
sret
用伪代码来看,encl_trap_handler最终会根据异常/中断分发到不同的函数,再根据scause执行不同的中断处理函数。
if (interrupt){
switch(cause) {
case INTERRUPT_CAUSE_TIMER:
handle_timer_interrupt();
break;
/* ignore other interrupts */
case INTERRUPT_CAUSE_SOFTWARE:
case INTERRUPT_CAUSE_EXTERNAL:
default:
sbi_stop_enclave(0);
return;
}
}else{
switch(cause){
case 8:
handle_syscall();
break;
case 13:
rt_page_fault();
break;
case 15:
rt_page_fault();
break;
default:
not_implemented_fatal();
break;
}
}
对于异常而言,not_implemented_fatal最终执行了sbi_stop_enclave(0),rt_page_fault最终执行了sbi_exit_enclave(-1)。handle_syscall()比较复杂,最后再详细介绍。
对于中断而言,时钟中断调用了handle_timer_interrupt(),如果是软件中中断或者外部中断会调用sbi_stop_enclave(0)。
那么总体来说,中断处理最终调用的函数分别是sbi_stop_enclave(0),sbi_exit_enclave(-1),handle_timer_interrupt(),handle_syscall()。
sbi_stop_enclave(0),sbi_exit_enclave(-1)实际上就是调用了SM的服务,切换到了M-mode,具体执行了哪些操作,我将在最后的SM章节进行分析。这里我们只讨论时钟中断的处理和handle_syscall()
时钟中断的处理
#define DEFAULT_CLOCK_DELAY 10000
void init_timer(void)
{
sbi_set_timer(get_cycles64() + DEFAULT_CLOCK_DELAY);
csr_set(sstatus, SR_SPIE);
csr_set(sie, SIE_STIE | SIE_SSIE);
}
void handle_timer_interrupt()
{
sbi_stop_enclave(0);
unsigned long next_cycle = get_cycles64() + DEFAULT_CLOCK_DELAY;
sbi_set_timer(next_cycle);
csr_set(sstatus, SR_SPIE);
return;
}
handle_syscall()
void handle_syscall(struct encl_ctx* ctx)函数用于实现系统调用。在这里会介绍一些比较关键且复杂的系统调用,其它的系统调用读者可自行翻阅源码。
在sdk/include/app/syscall.h中声明了runtime为eapp提供的系统服务:
int
copy_from_shared(void* dst, uintptr_t offset, size_t data_len);
int
ocall(
unsigned long call_id, void* data, size_t data_len, void* return_buffer,
size_t return_len);
uintptr_t
untrusted_mmap();
int
attest_enclave(void* report, void* data, size_t size);
int
get_sealing_key(
struct sealing_key* sealing_key_struct, size_t sealing_key_struct_size,
void* key_ident, size_t key_ident_size);
copy_from_shared
int
copy_from_shared(void* dst, uintptr_t offset, size_t data_len) {
return SYSCALL_3(SYSCALL_SHAREDCOPY, dst, offset, data_len);
}
eapp调用copy_from_shared之后陷入到内核中,在runtime中处理该系统调用的函数是handle_copy_from_shared:
// 这个函数实际上执行的就是
// copy_to_use(dst, _shared_buffer + offset, size);
uintptr_t handle_copy_from_shared(void* dst, uintptr_t offset, size_t size){
/* This is where we would handle cache side channels for a given
platform */
/* The only safety check we do is to confirm all data comes from the
* shared region. */
uintptr_t src_ptr;
// 实际上执行的就是 src_ptr = _shared_buffer + offset;
if(edge_call_get_ptr_from_offset(offset, size,
&src_ptr) != 0){
return 1;
}
return copy_to_user(dst, (void*)src_ptr, size);
}
OCALL
ocall()函数的目的是让eapp能够调用到host app提供的函数支持。
// sdk/src/app/syscall.c
int
ocall(
unsigned long call_id, void* data, size_t data_len, void* return_buffer,
size_t return_len) {
return SYSCALL_5(
SYSCALL_OCALL, call_id, data, data_len, return_buffer, return_len);
}
ocall函数是sdk为eapp调用host app提供的接口,eapp调用ocall()之后就会陷入到handle_syscall()中。在runtime中,ocall的实现为:
case(RUNTIME_SYSCALL_OCALL):
ret = dispatch_edgecall_ocall(arg0, (void*)arg1, arg2, (void*)arg3, arg4);
break;
dispatch_edgecall_ocall注释如下:
// defined in eyrie-runtime/src/syscall.c
// 如果读者还对前文中host与enclave的通信有印象,不难发现
// * call_id 就是 register_call 注册服务时使用的服务号,eapp也要使用服务号来调用相应的服务
// * data eapp调用ocall时传入的数据的地址
// * data_len 传入数据大小,以字节为单位
// * return_buffer host app返回的数据指针
// * return_len 返回的数据大小
uintptr_t dispatch_edgecall_ocall( unsigned long call_id,
void* data, size_t data_len,
void* return_buffer, size_t return_len){
uintptr_t ret;
/* For now we assume by convention that the start of the buffer is
* the right place to put calls */
// shared_buffer 声明在 vm.h,定义在 vm.c,初始化在 boot.c中的eyrie_boot函数
// 这是一个全局变量,尽管没有加锁也是无所谓的
// 因为每一个eapp都有一个runtime,而eapp又是不支持多线程的,因此不需要加锁
// shared_buffer 指向的是 utm
struct edge_call* edge_call = (struct edge_call*)shared_buffer;
/* We encode the call id, copy the argument data into the shared
* region, calculate the offsets to the argument data, and then
* dispatch the ocall to host */
edge_call->call_id = call_id;
// 实际上就是 shared_buffer + sizeof(struct edge_call);
// 为 struct edge_call 留出空间
uintptr_t buffer_data_start = edge_call_data_ptr();
if(data_len > (shared_buffer_size - (buffer_data_start - shared_buffer))){
goto ocall_error;
}
//TODO safety check on source
// 将数据从用户空间拷贝到 内核空间
copy_from_user((void*)buffer_data_start, (void*)data, data_len);
// 这个函数是定义在 sdk/src/edge/edge_call.c 中
// 这个函数就做了两件事
// edge_call->call_arg_size = data_len;
// edge_call->call_arg_offset = buffer_data_start - shared_buffer;
if(edge_call_setup_call(edge_call, (void*)buffer_data_start, data_len) != 0){
goto ocall_error;
}
// 见SM篇,这里会陷入SM,再最终切换到host app,host APP通过resume最终切换回eapp
// ret 就是 sbi_call 的返回值,判断是否 SBI 运行成功
// host app 传输给 eapp 的数据也是通过 shared_buffer 传输的
// host app 的返回值记录在 edge_call->return_data.call_status 中
ret = sbi_stop_enclave(1);
if (ret != 0) {
goto ocall_error;
}
if(edge_call->return_data.call_status != CALL_STATUS_OK){
goto ocall_error;
}
if( return_len == 0 ){
/* Done, no return */
return (uintptr_t)NULL;
}
uintptr_t return_ptr;
size_t ret_len_untrusted;
// 该函数实际执行的过程是
// ret_len_untrusted = edge_call->return_data.call_ret_size;
// return_ptr = _shared_start + edge_call->return_data.call_ret_offset;
if(edge_call_ret_ptr(edge_call, &return_ptr, &ret_len_untrusted) != 0){
goto ocall_error;
}
/* Done, there was a return value to copy out of shared mem */
/* TODO This is currently assuming return_len is the length, not the
value passed in the edge_call return data. We need to somehow
validate these. The size in the edge_call return data is larger
almost certainly.*/
copy_to_user(return_buffer, (void*)return_ptr, return_len);
return 0;
ocall_error:
/* TODO In the future, this should fault */
return 1;
}
untrusted_mmap
这个接口,keystone enclave并未实现。
attest_enclave
int
attest_enclave(void* report, void* data, size_t size) {
return SYSCALL_3(SYSCALL_ATTEST_ENCLAVE, report, data, size);
}
当eapp调用attest_enclave会陷入到handle_syscall()中,下面是runtime实现,可以发现runtime是调用了SM的功能来为eapp服务的,具体attest_enclave的实现将在SM中进行讲解。
case(RUNTIME_SYSCALL_ATTEST_ENCLAVE):;
copy_from_user((void*)rt_copy_buffer_2, (void*)arg1, arg2);
ret = sbi_attest_enclave(rt_copy_buffer_1, rt_copy_buffer_2, arg2);
/* TODO we consistently don't have report size when we need it */
copy_to_user((void*)arg0, (void*)rt_copy_buffer_1, 2048);
//print_strace("[ATTEST] p1 0x%p->0x%p p2 0x%p->0x%p sz %lx = %lu\r\n",arg0,arg0_trans,arg1,arg1_trans,arg2,ret);
break;
get_sealing_key
int
get_sealing_key(
struct sealing_key* sealing_key_struct, size_t sealing_key_struct_size,
void* key_ident, size_t key_ident_size) {
return SYSCALL_4(
SYSCALL_GET_SEALING_KEY, sealing_key_struct, sealing_key_struct_size,
key_ident, key_ident_size);
}
当eapp调用get_sealing_key会陷入到handle_syscall()中,下面是runtime实现,可以发现runtime是调用了SM的功能来为eapp服务的,具体get_sealing_key的实现将在SM中进行讲解。
case(RUNTIME_SYSCALL_GET_SEALING_KEY):;
/* Stores the key receive structure */
uintptr_t buffer_1_pa = kernel_va_to_pa(rt_copy_buffer_1);
/* Stores the key identifier */
uintptr_t buffer_2_pa = kernel_va_to_pa(rt_copy_buffer_2);
if (arg1 > sizeof(rt_copy_buffer_1) ||
arg3 > sizeof(rt_copy_buffer_2)) {
ret = -1;
break;
}
copy_from_user(rt_copy_buffer_2, (void *)arg2, arg3);
ret = sbi_get_sealing_key(buffer_1_pa, buffer_2_pa, arg3);
if (!ret) {
copy_to_user((void *)arg0, (void *)rt_copy_buffer_1, arg1);
}
/* Delete key from copy buffer */
memset(rt_copy_buffer_1, 0x00, sizeof(rt_copy_buffer_1));
break;
其它系统调用
linux_wrap.c
linux_wrap.c实现的都是可以在runtime中直接实现而不需要调用SBI或者切换到Linux内核执行的函数。
我这里只列出已经实现的函数,左边是Linux提供的用户态的接口,右边是相应的runtime的内核态的实现:
| 内核态实现函数 | 支持程度 | |
|---|---|---|
| gettime | linux_clock_gettime | HALF |
| uname | linux_uname | FULL |
| munmap | syscall_munmap | HALF |
| mmap | syscall_mmap | HALF |
| brk | syscall_brk | HALF |
io_wrap.c
io相关的系统调用是委托给Linux内核的,那么基本过程与ocall是一致的。所以就不再特殊分析了。
net_wrap.c
net相关的系统调用也是委托给Linux内核执行的,基本过程与ocall一致,不再特殊分析。
Enable SSTATUS.SIE
其中sbi_stop_enclave(0),sbi_exit_enclave(-1)是调用了SM的服务,关于这两个函数究竟会再SM中做哪些处理先不管,我们先来讨论
TODO
我现在也没搞清楚,如果说调用了SBI的服务的函数,SBI会自动激活sstatus.sie的话,那么RUNTIME_SYSCALL_SHAREDCOPY类型的系统调用就完全无法理解了,因为真的没有激活中断呀!
SM
sbi_ecall
struct sbiret {
long error;
long value;
};
struct sbiret sbi_ecall(int ext, int fid, unsigned long arg0,
unsigned long arg1, unsigned long arg2,
unsigned long arg3, unsigned long arg4,
unsigned long arg5);
sbi_ecall 函数接受多个参数,它们分别是:
ext:SBI 扩展 ID,用于标识需要调用的 SBI 实现。不同的 SBI 实现会有不同的扩展 ID。例如,SBI v0.2 规范中定义了四个 SBI 扩展 ID,分别为 SBI 调试、SBI IPI、SBI 定时器和 SBI 控制台。fid:SBI 功能号,用于指定需要执行的具体操作。每个 SBI 扩展 ID 都会定义一组功能号,表示支持的不同操作。例如,SBI 调试扩展中定义了可以设置/清除断点、读取/写入寄存器等多个功能号。arg0~arg5:SBI 请求参数,根据 SBI 规范的要求,这些参数需要按照特定的顺序和规则进行传递。具体来说,arg0~arg5 对应了 a0~a5 这六个 RISC-V 通用寄存器,它们用于传递整型(unsigned long)的参数。如果请求需要传递指针或其他类型的参数,则需要将其转换为 unsigned long 后传递。
注意:在 SBI 规范中,只规定了前五个参数的用途和传递方式,即 s0-s4 寄存器中包含的参数 arg0~arg4,而 arg5 只是为了方便扩展而存在,具体使用方法由不同的 SBI 扩展自行定义。但是在实际使用中,有些 SBI 实现会在 arg5 中传递一些额外的参数或者指针,以满足特定的需求。
keystone-linux-driver与sm的通信
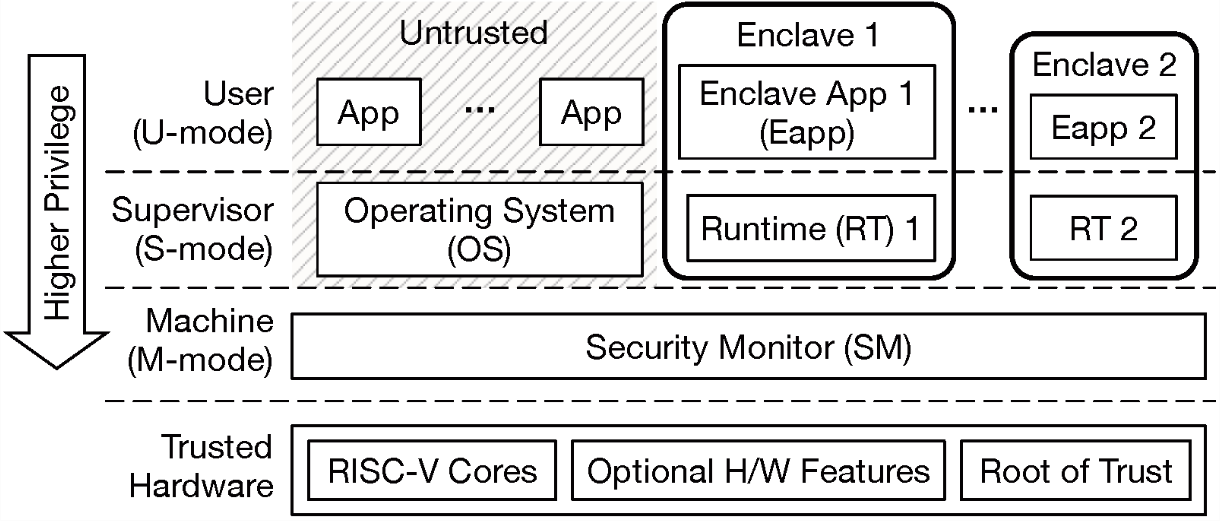
enclave是怎么运行起来的
如下图所示,是keystone的特权级架构图。为了便于描述,我们将Normal World的特权级分别称之为NU和NS,enclave的特权级分别称之为EU和ES。
我们看到host app是运行在NU的,eapp是运行在EU的,我们要将eapp加载到EU,必然涉及到特权级的转换,因为从图中不难看出,normal world与enclave是相互隔离的,只有SM才能够在normal world与enclave之间相互切换。我们在分析SDK的内存管理以及SDK的Enclave类的时候已经透彻的讲述了enclave内存是如何被创建的以及eapp和runtime二进制文件是如何被加载到enclave内存当中的。最后host app通过调用Enclave::run()函数运行起来了enclave。那么这个运行过程是怎么实现的呢?
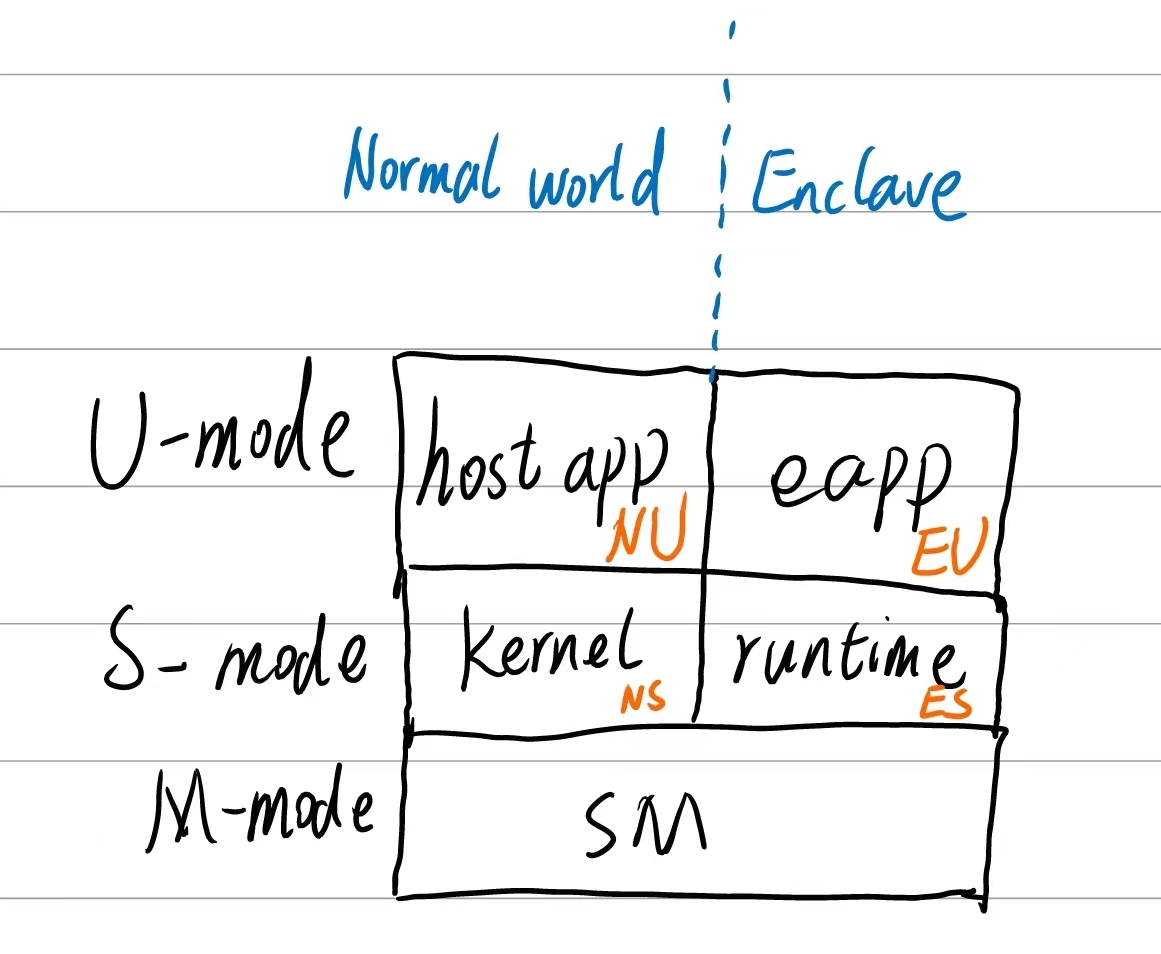
enclave的运行
好了,现在让我们开始分析enclave究竟是怎么运行起来的。
在前文中我们已经讲解过了Enclave::runrun((不考虑模拟器的情况)。
KeystoneDevice::run__run(,这里会区分是恢复enclave的运行还是运行。如果resume为true那么就是恢复被中断的enclave继续运行,否则就是第一次运行。之后会调用ioctl函数,跳入到keystone linux driver,这样就从NU特权级切换到了NS特权级。怎么切换的呢?当然是调用ecall啦,读者可以自行查看ioctl的源码实现以及特权级切换的过程。
现在我们看一下keystone linux driver的代码,仅仅是小窥一眼,后续会详细介绍驱动代码。我们知道是要运行enclave,host app在调用ioctl之后就会跳入到keystone_run_enclave()函数。在这个函数中会调用sbi_sm_run_enclave函数,该函数会调用sbi_ecall(KEYSTONE_SBI_EXT_ID, SBI_SM_RUN_ENCLAVE, eid, 0, 0, 0, 0, 0)这样就切换到了M-mode,CPU会开始执行SM的代码。
下面我们看看SM,SM本质上是对opensbi的拓展。后文中会详细介绍SM的实现,这里看一下,sbi_ecall函数执行后跳入到哪里。
sbi_ecall函数会跳入到SM的sbi_ecall_keystone_enclave_handler()然后执行sbi_sm_run_enclave函数,该函数会调用run_enclave(),该函数会调用context_switch_to_enclave函数。在该函数中会为enclave准备必要的环境,并设置PMP(physical memory protect,读者自行查阅相关资料)。
context_switch_to_enclave函数准备的环境比较多,比较关键的是regs->mepc = (uintptr_t) enclaves[eid].params.runtime_entry - 4这设置regs上下文的mepc指向runtime入口点地址再减去4的地方。之所以会减去4是因为,在sbi_ecall_handler函数返回之前会自动将regs->mepc的值加4,这样在返回S-mode的时候会恢复寄存器上下文,由于mepc此时就会指向运行时的入口地址,CPU就会开始执行runtime的代码,runtime在设置好相关环境之后就会跳转到eapp的入口地址开始执行eapp。
SDK-edge Lib 边缘调用
Edge Lib Overview
SDK中的edge库,是为enclave提供的用于调用host端代码的一系列函数。在sdk/src/edge中有三个c文件,其中edge_dispatch.c中的incoming_call_dispatch函数用于分发eapp调用host端函数时调用正确的函数,host则使用register_call函数将host端的函数注册进edge_call_table数组中。edge_syscall.c的提供的功能与edge_dispatch.c相似,只不过edge_dispatch.c是分发的是运行在U-MODE的用户自定义的函数,edge_syscall.c分发的是若干Linux系统调用函数,比如openat()、unlinkat()、write()等。edge_syscall.c提供的incoming_syscall函数首先也是在 edge_dispatch.c中的incoming_call_dispatch函数进行分发的。
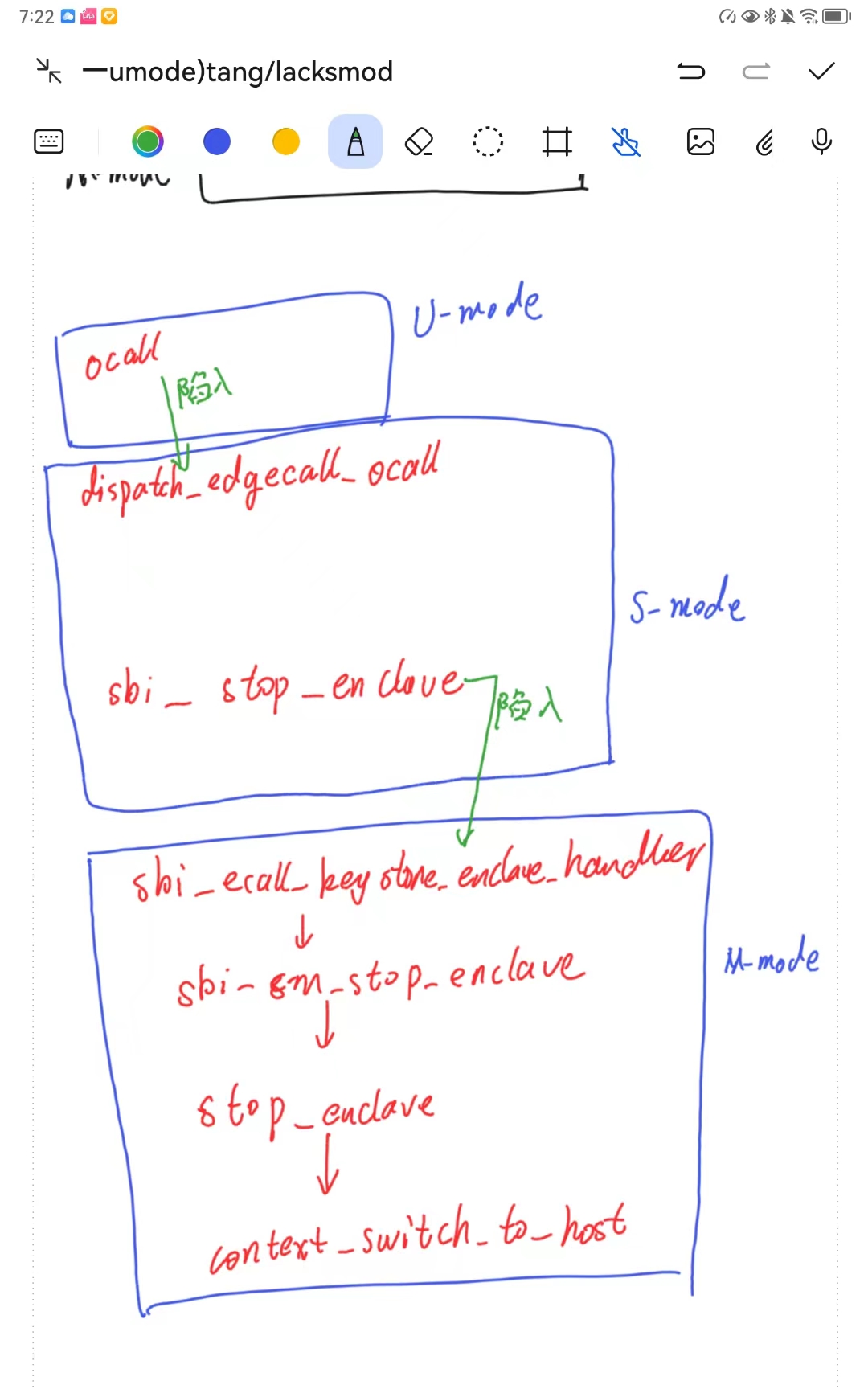
host与enclave的通信样例
以sdk/examples/hello-native为例,host code和eapp code分别如下:
// host code
// 编译出的二进制文件名称为 hello-native-runner
#include <edge_call.h>
#include <keystone.h>
unsigned long
print_string(char* str);
void
print_string_wrapper(void* buffer);
#define OCALL_PRINT_STRING 1
/***
* An example call that will be exposed to the enclave application as
* an "ocall". This is performed by an edge_wrapper function (below,
* print_string_wrapper) and by registering that wrapper with the
* enclave object (below, main).
***/
unsigned long
print_string(char* str) {
return printf("Enclave said: \"%s\"\n", str);
}
int
main(int argc, char** argv) {
Keystone::Enclave enclave;
Keystone::Params params;
params.setFreeMemSize(1024 * 1024);
params.setUntrustedMem(DEFAULT_UNTRUSTED_PTR, 1024 * 1024);
enclave.init(argv[1], argv[2], params);
// 定义在 sdk/src/edge/edge_dispatch.c
// 我们在 Enclave::run() 函数中可以看到,当从 enclave 返回到 host 端时
// 就会调用 Enclave::oFuncDispatch 函数句柄,这个句柄就是在此处被初始化的
// 后文会详细解释 incoming_call_dispatch
enclave.registerOcallDispatch(incoming_call_dispatch);
/* We must specifically register functions we want to export to the
enclave. */
// 注册自定义的函数句柄,OCALL_PRINT_STRING 是 call_id, print_string_wrapper 是函数句柄
// eapp 在尝试调用 print_string_wrapper 时,host端会根据
// eapp 提供的 call_id 找到对应的函数句柄
// 这个函数也很简单,其实就是 edge_call_table[call_id] = func
// 之后 eapp 尝试调用 host 端的代码时,就会提供 call_id
// host 就根据 call_id 查询 edge_call_table 表就能找到对应的函数句柄,然后调用之
// host 中根据 call_id 查询函数句柄的过程就是 incoming_call_dispatch 函数实现的
register_call(OCALL_PRINT_STRING, print_string_wrapper);
// 这里的函数很简单,其实就是记录了 UTM 的起始地址和大小
edge_call_init_internals(
(uintptr_t)enclave.getSharedBuffer(), enclave.getSharedBufferSize());
enclave.run();
return 0;
}
/***
* Example edge-wrapper function. These are currently hand-written
* wrappers, but will have autogeneration tools in the future.
***/
void
print_string_wrapper(void* buffer) {
/* Parse and validate the incoming call data */
struct edge_call* edge_call = (struct edge_call*)buffer;
uintptr_t call_args;
unsigned long ret_val;
size_t arg_len;
if (edge_call_args_ptr(edge_call, &call_args, &arg_len) != 0) {
edge_call->return_data.call_status = CALL_STATUS_BAD_OFFSET;
return;
}
/* Pass the arguments from the eapp to the exported ocall function */
ret_val = print_string((char*)call_args);
/* Setup return data from the ocall function */
uintptr_t data_section = edge_call_data_ptr();
memcpy((void*)data_section, &ret_val, sizeof(unsigned long));
if (edge_call_setup_ret(
edge_call, (void*)data_section, sizeof(unsigned long))) {
edge_call->return_data.call_status = CALL_STATUS_BAD_PTR;
} else {
edge_call->return_data.call_status = CALL_STATUS_OK;
}
/* This will now eventually return control to the enclave */
return;
}
//eapp code
// 编译出的二进制文件名称为 hello-native
#include "eapp_utils.h"
#include "string.h"
#include "edge_call.h"
#include <syscall.h>
#define OCALL_PRINT_STRING 1
unsigned long ocall_print_string(char* string);
int main(){
ocall_print_string("Hello World");
EAPP_RETURN(0);
}
unsigned long ocall_print_string(char* string){
unsigned long retval;
// ocall 是调用 host 函数的接口
// OCALL_PRINT_STRING 就是call_id,这是在host端注册的
ocall(OCALL_PRINT_STRING, string, strlen(string)+1, &retval ,sizeof(unsigned long));
return retval;
}
eapp 调用 host 函数流程
我们在前文中绘制了eapp在调用ocall()之后的执行流,会陷入到runtime中,由dispatch_edgecall_ocall函数负责对eapp的数据进行封装。在dispatch_edgecall_ocall函数中,会使用到SDK提供的struct edge_call结构体,runtime就是将所有的数据打包到这个结构体中
会最终调用到SM的stop_enclave函数。
SDK为edge call提供的数据结构
/* Useful type for things like packaged strings, etc */
struct edge_data {
edge_data_offset offset;
size_t size;
};
struct edge_app_retdata {
void* app_ptr;
size_t len;
};
struct edge_return {
/* Status variable indicating error/success conditions. Not for data
values. */
unsigned long call_status;
/* OFFSET into the shared memory region. Should be checked for
* validity, then turned into a pointer to a relevant return data
* structure for the call. (User/call defined) */
edge_data_offset call_ret_offset;
size_t call_ret_size;
};
struct edge_call {
/* Similar to syscall number. User-defined call id, handled at the
* edges only */
unsigned long call_id;
/* OFFSET into the shared memory region. Should be checked for
* validity, then turned into a pointer to a relevant argument
* structure for the call. (User/call defined)*/
edge_data_offset call_arg_offset;
size_t call_arg_size;
/* Pre-set location to structure return data */
struct edge_return return_data;
};
edge_call.c分析
// 这两个全局变量分别用于记录 UTM 的起始地址和大小
// UTM 是用于 enclave 与 host 通信的
// UTM 在 Enclave::init() 中被创建,并使用 map 映射到 host 的虚拟内存中
// UTM 虚拟地址的虚拟地址记录在 Enclave::shared_buffer 变量中
// 因此我们可以看到在样例中是使用 enclave.getSharedBuffer() 来获取该变量的值的
uintptr_t _shared_start;
size_t _shared_len;
// host 调用,用于记录 UTM 的起始地址和大小
void
edge_call_init_internals(uintptr_t buffer_start, size_t buffer_len) {
_shared_start = buffer_start;
_shared_len = buffer_len;
}
int
edge_call_get_ptr_from_offset(
edge_data_offset offset, size_t data_len, uintptr_t* ptr) {
// TODO double check these checks
/* Validate that _shared_start+offset is sane */
if (offset > UINTPTR_MAX - _shared_start || offset > _shared_len) {
return -1;
}
/* Validate that _shared_start+offset+data_len in range */
if (data_len > UINTPTR_MAX - (_shared_start + offset) ||
data_len > _shared_len - offset) {
return -1;
}
/* ptr looks valid, create it */
*ptr = _shared_start + offset;
return 0;
}
int
edge_call_check_ptr_valid(uintptr_t ptr, size_t data_len) {
// TODO double check these checks
/* Validate that ptr starts in range */
if (ptr > _shared_start + _shared_len || ptr < _shared_start) {
return 1;
}
if (data_len > UINTPTR_MAX - ptr) {
return 2;
}
/* Validate that the end is in range */
if (ptr + data_len > _shared_start + _shared_len) {
return 3;
}
return 0;
}
int
edge_call_get_offset_from_ptr(
uintptr_t ptr, size_t data_len, edge_data_offset* offset) {
int valid = edge_call_check_ptr_valid(ptr, data_len);
if (valid != 0) return valid;
/* ptr looks valid, create it */
*offset = ptr - _shared_start;
return 0;
}
int
edge_call_args_ptr(struct edge_call* edge_call, uintptr_t* ptr, size_t* size) {
*size = edge_call->call_arg_size;
return edge_call_get_ptr_from_offset(edge_call->call_arg_offset, *size, ptr);
}
int
edge_call_ret_ptr(struct edge_call* edge_call, uintptr_t* ptr, size_t* size) {
*size = edge_call->return_data.call_ret_size;
return edge_call_get_ptr_from_offset(
edge_call->return_data.call_ret_offset, *size, ptr);
}
int
edge_call_setup_call(struct edge_call* edge_call, void* ptr, size_t size) {
edge_call->call_arg_size = size;
return edge_call_get_offset_from_ptr(
(uintptr_t)ptr, size, &edge_call->call_arg_offset);
}
int
edge_call_setup_ret(struct edge_call* edge_call, void* ptr, size_t size) {
edge_call->return_data.call_ret_size = size;
return edge_call_get_offset_from_ptr(
(uintptr_t)ptr, size, &edge_call->return_data.call_ret_offset);
}
/* This is only usable for the host */
int
edge_call_setup_wrapped_ret(
struct edge_call* edge_call, void* ptr, size_t size) {
struct edge_data data_wrapper;
data_wrapper.size = size;
edge_call_get_offset_from_ptr(
_shared_start + sizeof(struct edge_call) + sizeof(struct edge_data),
sizeof(struct edge_data), &data_wrapper.offset);
memcpy(
(void*)(_shared_start + sizeof(struct edge_call) + sizeof(struct edge_data)),
ptr, size);
memcpy(
(void*)(_shared_start + sizeof(struct edge_call)), &data_wrapper,
sizeof(struct edge_data));
edge_call->return_data.call_ret_size = sizeof(struct edge_data);
return edge_call_get_offset_from_ptr(
_shared_start + sizeof(struct edge_call), sizeof(struct edge_data),
&edge_call->return_data.call_ret_offset);
}
/* This is temporary until we have a better way to handle multiple things */
uintptr_t
edge_call_data_ptr() {
return _shared_start + sizeof(struct edge_call);
}